QuestDB 9.4.0: Posting index, cross-column fill, and smarter Web Console
QuestDB 9.4.0 ships a new index type for SYMBOL columns that is 13x smaller
than the bitmap index, a FILL(PREV(col)) syntax that carries values across
columns in SAMPLE BY, and a smarter Web Console that generates materialized
view definitions and filters autocompletion by grammar context. Also in this
release: three new window functions, sparkline() / bar() text
visualizations, and speed-ups across GROUP BY, hash joins, and top-K queries.
Posting index for SYMBOL columns
The existing bitmap index works well for low-cardinality symbols, but it struggles on wide tables with hundreds or thousands of distinct values. The new posting index is built for exactly that scenario: 13x smaller index files, 1.3-1.5x faster lookups, at roughly 9% write-amplification cost.
Create it on a new table:
CREATE TABLE trades_pi (ts TIMESTAMP,sym SYMBOL INDEX TYPE POSTING,price DOUBLE,qty INT) TIMESTAMP(ts) PARTITION BY DAY;
Or add it to an existing column:
ALTER TABLE my_tableALTER COLUMN sym ADD INDEX TYPE POSTING;
Covering index
The real payoff comes when you add an INCLUDE clause. This builds a covering
sidecar so queries that only need the indexed column plus the included columns
skip the main column files entirely:
ALTER TABLE my_tableALTER COLUMN sym ADD INDEX TYPE POSTINGINCLUDE (price, qty);
Queries of the form WHERE sym = 'X', WHERE sym IN (...),
LATEST ON ts PARTITION BY sym, and SELECT DISTINCT sym all benefit from the
covering path. Covering data is ALP-compressed for floats, FoR bit-packed for
integers, and FSST-compressed for strings. AVX2 decoding kicks in on supported
hardware.
Use EXPLAIN to verify a query is using the covering path. The plan shows
CoveringIndex on: sym with: ....
WARNING
Drop the posting index before rolling back to a pre-9.4.0 binary. Older
versions do not recognise the new index type and will refuse to open the table.
Run ALTER TABLE <t> ALTER COLUMN <sym> DROP INDEX on every posting-indexed
column first.
Read the posting index documentation
Cross-column FILL(PREV) and parallel SAMPLE BY FILL
Say you have a stream of FX quotes and you want one-minute bars of average bid
and ask. On quiet minutes, both prices should carry forward the last known ask
price, not the last bid for one and the last ask for the other, which is what
FILL(PREV, PREV) gives you. Before 9.4.0, you needed a CTE with
last_value(...) IGNORE NULLS OVER (...) and a coalesce per column.
Now it is a one-liner:
SELECT timestamp, symbol,avg(bid_price) AS bid_price,avg(ask_price) AS ask_priceFROM core_priceWHERE symbol = 'EURUSD'AND timestamp IN '$today'SAMPLE BY 100TFILL(PREV(ask_price), PREV);
FILL(PREV(ask_price)) on the bid_price aggregate carries forward the
previous value of ask_price instead of bid_price. The reference must match
the target column's type and is rejected when either side is a SYMBOL.
FILL(NULL), FILL(<constant>), and bare FILL(PREV) can be mixed freely in
the same fill list.
At the same time, SAMPLE BY FILL(NULL | <constant> | PREV) has moved from
the sequential cursor path onto the parallel GROUP BY engine. Keyed queries
on wide tables benefit the most. Keyed FROM-TO with constant bounds is also
now supported natively.
Other fixes that ride along:
- Sub-day
SAMPLE BYwithTIME ZONEandFROM/TOno longer misaligns the fill grid by the timezone offset ALIGN TO CALENDAR WITH OFFSETcombined withFILLno longer falls into an infinite fill loopSAMPLE BY FILLnow works on tables with pre-1970 timestamps
Read the SAMPLE BY FILL documentation
New window functions: ntile(), cume_dist(), nth_value()
QuestDB's window function
library picks up three SQL-standard additions. All three honour PARTITION BY
and ORDER BY:
ntile(n) distributes rows into n approximately equal buckets. Useful for
percentile-based bucketing:
SELECT symbol, price, amount,ntile(4) OVER (PARTITION BY symbolORDER BY amount DESC) AS volume_quartileFROM tradesWHERE symbol = 'BTC-USDT'AND timestamp IN '$today'LIMIT 20;
cume_dist() returns the cumulative distribution of the current row within
its partition, as a value between 0 and 1:
SELECT symbol, price, amount,cume_dist() OVER (PARTITION BY symbolORDER BY price) AS price_percentileFROM tradesWHERE symbol = 'BTC-USDT'AND timestamp IN '$today'LIMIT 20;
nth_value(expr, n) returns the n-th value within the current frame.
Supports DOUBLE, LONG, and TIMESTAMP arguments with both ROWS and
RANGE frames:
SELECT symbol, timestamp, price,nth_value(price, 1) OVER w AS open_price,last_value(price) OVER w AS latest_priceFROM tradesWHERE symbol = 'BTC-USDT'AND timestamp IN '$today'WINDOW w AS (PARTITION BY symbolORDER BY timestampROWS BETWEEN UNBOUNDED PRECEDINGAND CURRENT ROW)LIMIT 20;
Text visualizations: sparkline() and bar()
We wrote about the
text visualization functions
a couple of weeks ago when they were still unreleased. bar() and sparkline()
now ship in 9.4.0.
sparkline() is an aggregate that renders a trend line across grouped values
with auto-scaling:
SELECT symbol, sparkline(price) AS trendFROM tradesWHERE timestamp IN '$today'SAMPLE BY 1h;
bar() is a scalar that renders a single value as a horizontal bar with eight
levels of sub-character precision:
SELECT timestamp, symbol,count() AS trades,bar(count(), 0, 20000, 30) AS activityFROM tradesWHERE timestamp IN '$today'SAMPLE BY 1h;
Both return VARCHAR and work across all clients: Web Console, psql,
JDBC, anything that can display Unicode.
The trading-specific functions from that post, ohlc_bar() and
depth_chart(), are still under review in
questdb/questdb#7039 and will
follow in an upcoming release.
Read the visualization functions documentation
Web Console
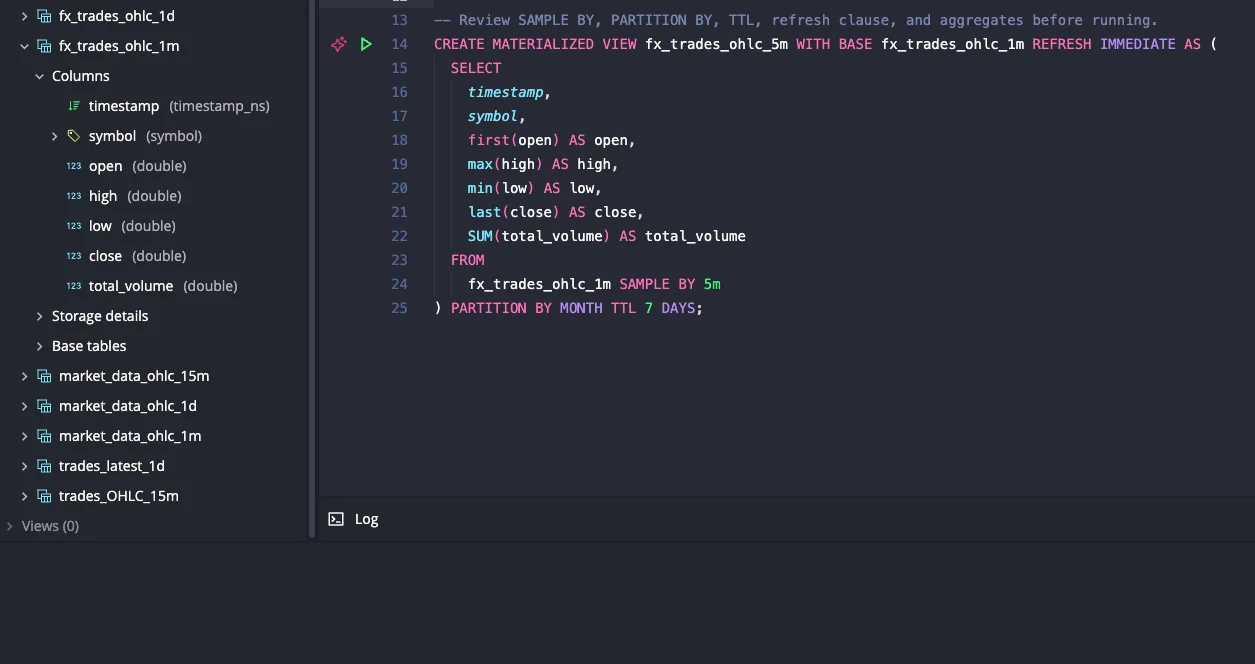
Create materialized view from the table menu. Right-click a table (or an
existing materialized view) and the console generates a starter
CREATE MATERIALIZED VIEW statement with inferred SAMPLE BY, PARTITION BY,
and TTL settings. From an existing materialized view, it produces a downsample
one rung up the SAMPLE BY ladder. Disabled on non-WAL tables and tables
without a designated timestamp.
Context-aware SQL autocompletion. Function suggestions now filter by grammar
context. WHERE price = c| shows scalars only (coalesce, concat, cos,
ceil) instead of mixing in aggregates. ASOF JOIN m| shows table names, not
the full function list. INSERT INTO ... VALUES (n| now suggests now,
now_ns, nullif. The editor also no longer hangs on a trailing comma in the
SELECT list.
Performance
- Parallel keyed
GROUP BY: batched aggregate dispatch eliminates per-row virtual calls on the reducer. Up to 4.6x speed-up on single-columncount()over fixed-size keys and 1.4-1.8x on multi-aggregate queries. Also fixes a correctness bug incount(uuid)for UUIDs whose high half equalsLong.MIN_VALUE. GROUP BY, hash joins, andcount_distinct: a faster xxh3-derived hash finalizer and denser hash tables shave 15-25% off manyGROUP BYqueries and improve worst-case probe behaviour by orders of magnitude on adversarial inputs. ClickBench total time improves by 1.2% across 43 queries.- Parallel top-K with
SELECTprojections:ORDER BY ... LIMIT Nnow uses the parallel top-K path even when a column projection sits between the limit and the filtered scan. - Timestamp equality filters: comparing a
TIMESTAMPcolumn against a string bind variable no longer re-parses the value on every row. - Lateral join decorrelation: shared sub-query computations now execute once instead of being cloned per correlated reference.
Parquet metadata sidecar
Each Parquet partition now ships with a compact binary _pm sidecar that stores
column descriptors, per-row-group byte ranges, encodings, and min/max
statistics. The query planner reads pruning information from _pm without
opening data.parquet, which is a prerequisite for efficient cold-storage scans.
A migration generates _pm files for all existing Parquet partitions on engine
upgrade.
Separately, PARQUET_ENCODING(...) now propagates through projected streaming
Parquet exports, so COPY (SELECT ...) TO ... WITH format parquet and
/exp?query=... preserve the configured encoding instead of silently reverting
to defaults.
Bug fixes
This release includes fixes across the SQL planner, WAL apply path, and PGWire
protocol. Highlights include corrections to window functions nested inside
GROUP BY, BETWEEN inside sub-expressions, WINDOW JOIN with symbol
projections, and memory corruption from malformed PGWire messages.
See the full list on the release notes page.
That is QuestDB 9.4.0. The posting index changes how you think about SYMBOL
column lookups on wide tables, cross-column FILL(PREV) removes a whole class
of workarounds in time-series sampling, and sparkline() lets you spot trends
without leaving the SQL console.
Ready to try it?
docker pull questdb/questdbdocker run -p 9000:9000 -p 8812:8812 questdb/questdb
Join our Slack or Discourse communities to share feedback and results.