Benchmark and comparison: QuestDB vs. ClickHouse
last updated March 18, 2026 Benchmarks for ClickHouse 26.2.4.23 and QuestDB 9.3.3.
In this article:
- Two databases, different strengths
- Performance benchmarks
- Architecture
- Openness and data formats
- ClickHouse limitations
- QuestDB limitations
- Conclusion
Two databases, different strengths
QuestDB and ClickHouse are both fast analytical databases, but they come from different worlds and solve different problems.
QuestDB is built for high-throughput streaming ingestion and low-latency queries. It works efficiently at any batch size, from single rows to large batches, and sits on the critical path for some of the fastest markets out there: capital markets, trading, defense, energy, and now robotics. It was conceived on low-latency trading floors in the most demanding desks such as eFX at tier-1 investment banks. It is lightweight and designed to work out of the box. Written in zero-GC Java and C++, licensed under Apache 2.0. The enterprise edition adds a Rust-based infrastructure layer for high availability and elastic scaling.
ClickHouse is an OLAP engine with a wider range of use cases. It started at Yandex for e-commerce and ad tech analytics, and its SQL primitives reflect that heritage. Today it powers log monitoring, observability, and product analytics, with a growing ecosystem that positions it as an alternative to tools like Datadog and as a destination for data coming out of OLTP systems like Postgres. Streaming ingestion is not its key strength; ClickHouse is more optimized for batch loading and has been moving toward the standard warehousing model in the vein of Snowflake. Written in C++, also Apache 2.0.
The two databases don't compete head-to-head on most workloads. That said, it is natural for engineering teams to evaluate both when looking for a fast analytical engine, so this article provides a fair comparison on performance, architecture, and ease of use.
| Aspect | QuestDB | ClickHouse |
|---|---|---|
| License | Apache 2.0 | Apache 2.0 |
| Implementation | Zero-GC Java, C++ | C++ |
| Query language | SQL with time-series extensions | SQL (ClickHouse dialect) |
| Data model | Relational (tables + rows) | Relational (tables + rows) |
| Ingestion protocols | ILP, PostgreSQL wire, HTTP | HTTP, Native protocol, Kafka, OpenTelemetry |
| Primary use case | Time series, capital markets, streaming | OLAP, observability (logs/traces/metrics) |
Performance benchmarks
Summary (TSBS benchmark): QuestDB is 4.1-4.8x faster on ingestion and 27x faster on lastpoint queries. For analytical queries, QuestDB is 3.4-4.9x faster on short-range point lookups and 1.3x faster on heavy scans, while ClickHouse is 2.1x-2.3x faster on 12-hour range queries and 1.2x faster on some double-groupby aggregations.
We use the open-source Time Series Benchmark Suite (TSBS) for all benchmarks, which supports both ClickHouse and QuestDB out of the box.
Hardware: AWS EC2 r8a.8xlarge (32 vCPU, 256 GB RAM, AMD EPYC), GP3 EBS storage (20,000 IOPS, 1 GB/s throughput)
Software: Ubuntu 22.04, ClickHouse 26.2.4.23, QuestDB 9.3.3 - all with default configurations
Ingestion benchmark
We test a cpu-only scenario with two days of CPU data for various numbers of simulated hosts (100, 1K, 4K, 100K, and 1M). This tests how each database handles increasing data volumes and cardinality.
In time-series databases, high cardinality means having many unique values in indexed columns (millions of unique symbols, account IDs, or trading venues). More hosts in this benchmark means higher cardinality.
Commands to generate and ingest data for 4K hosts at 10s intervals:
$ ./tsbs_generate_data --use-case="cpu-only" --seed=123 --scale=4000 \--timestamp-start="2016-01-01T00:00:00Z" \--timestamp-end="2016-01-03T00:00:00Z" \--log-interval="10s" --format="clickhouse" > /tmp/clickhouse_data$ ./tsbs_load_clickhouse --db-name=benchmark --file=/tmp/clickhouse_data \--host=localhost --workers=32
The results for ingestion with 32 workers:
Higher is better
| Scale | ClickHouse | QuestDB | QuestDB vs ClickHouse |
|---|---|---|---|
| 100 hosts | 1.74M rows/sec | 7.77M rows/sec | QuestDB 4.5x faster |
| 1,000 hosts | 1.74M rows/sec | 7.77M rows/sec | QuestDB 4.5x faster |
| 4,000 hosts | 1.74M rows/sec | 7.96M rows/sec | QuestDB 4.6x faster |
| 100,000 hosts | 1.78M rows/sec | 8.59M rows/sec | QuestDB 4.8x faster |
| 1,000,000 hosts | 1.74M rows/sec | 7.14M rows/sec | QuestDB 4.1x faster |
Key observations:
- QuestDB is 4.1x to 4.8x faster than ClickHouse across all cardinality levels
- ClickHouse holds steady at ~1.74M rows/sec regardless of cardinality
- QuestDB delivers 7-8.6M rows/sec, peaking at 8.59M rows/sec at 100K hosts
- QuestDB's WAL-based architecture avoids merge overhead during ingestion
- ClickHouse can reach higher throughput with tuning (parallel threads, block sizes, async inserts), but that requires configuration work. QuestDB hits these numbers with defaults
Query performance
Ingestion is only half the story. Here are the query benchmarks from the standard TSBS suite:
- single-groupby: Aggregate CPU metrics for random hosts over specified time ranges
- double-groupby: Aggregate across ALL hosts, grouped by host and time intervals
- high-cpu: Finding hosts with CPU utilization above threshold (single host and all hosts)
- lastpoint: Retrieving the most recent data point per host
- groupby-orderby-limit: Top-N aggregation with ordering
All queries target two days of 4000 emulated host data.
To run the benchmark:
$ ./tsbs_generate_queries --use-case="devops" --seed=123 --scale=4000 \--timestamp-start="2016-01-01T00:00:00Z" \--timestamp-end="2016-01-03T00:00:00Z" \--queries=1000 --query-type="single-groupby-1-1-1" \--format="clickhouse" > /tmp/clickhouse_query$ ./tsbs_run_queries_clickhouse --file=/tmp/clickhouse_query \--db-name=benchmark --workers=1
Single-groupby queries
Lower is better
Query format: metrics-hosts-hours
| Query | ClickHouse | QuestDB | Best |
|---|---|---|---|
| single-groupby-1-1-1 | 3.96 ms | 1.00 ms | QuestDB 4x faster |
| single-groupby-1-1-12 | 3.98 ms | 9.34 ms | ClickHouse 2.3x faster |
| single-groupby-1-8-1 | 4.63 ms | 1.35 ms | QuestDB 3.4x faster |
| single-groupby-5-1-1 | 4.71 ms | 0.97 ms | QuestDB 4.9x faster |
| single-groupby-5-1-12 | 4.85 ms | 10.07 ms | ClickHouse 2.1x faster |
| single-groupby-5-8-1 | 6.67 ms | 1.44 ms | QuestDB 4.6x faster |
Double-groupby queries
These queries aggregate across ALL hosts, grouped by host and 1-hour intervals.
Lower is better
Aggregates across ALL hosts, grouped by host and 1-hour intervals
| Query | ClickHouse | QuestDB | Best |
|---|---|---|---|
| double-groupby-1 | 25.67 ms | 31.55 ms | ClickHouse 1.2x faster |
| double-groupby-5 | 39.43 ms | 43.15 ms | ClickHouse 1.1x faster |
| double-groupby-all | 62.22 ms | 58.55 ms | ~Tied |
Heavy queries
Finding hosts with CPU utilization above threshold.
Lower is better
Finding hosts with CPU utilization above threshold
| Query | ClickHouse | QuestDB | Best |
|---|---|---|---|
| high-cpu-1 | 19.54 ms | 5.47 ms | QuestDB 3.6x faster |
| high-cpu-all | 968.01 ms | 724.65 ms | QuestDB 1.3x faster |
Lastpoint and additional queries
Lower is better
| Query | ClickHouse | QuestDB | Best |
|---|---|---|---|
| lastpoint | 41.79 ms | 1.56 ms | QuestDB 27x faster |
| groupby-orderby-limit | 10.77 ms | 8.82 ms | QuestDB 1.2x faster |
The lastpoint query retrieves the most recent data point per host, one of the most common time-series operations. QuestDB's LATEST ON syntax is purpose-built for this pattern and completes in 1.56ms vs ClickHouse's 41.79ms. The groupby-orderby-limit query tests top-N aggregation, where QuestDB holds a slight edge.
Why these differences?
Both are columnar databases, but they make different architectural trade-offs that explain these results:
Why QuestDB wins on ingestion and point queries:
- Designated timestamp lets QuestDB prune time ranges without scanning
- JIT compilation compiles query filters to machine code at runtime
- Time-partitioned storage organizes data physically by time, which matches how time-series queries actually access data
Where ClickHouse architecture pays off:
- Flexible sorting via MergeTree's ORDER BY can optimize for non-time-based access patterns
- Distributed queries with native sharding for horizontal scalability
- Observability stack with native JSON type, inverted indices for text search, and OpenTelemetry integration
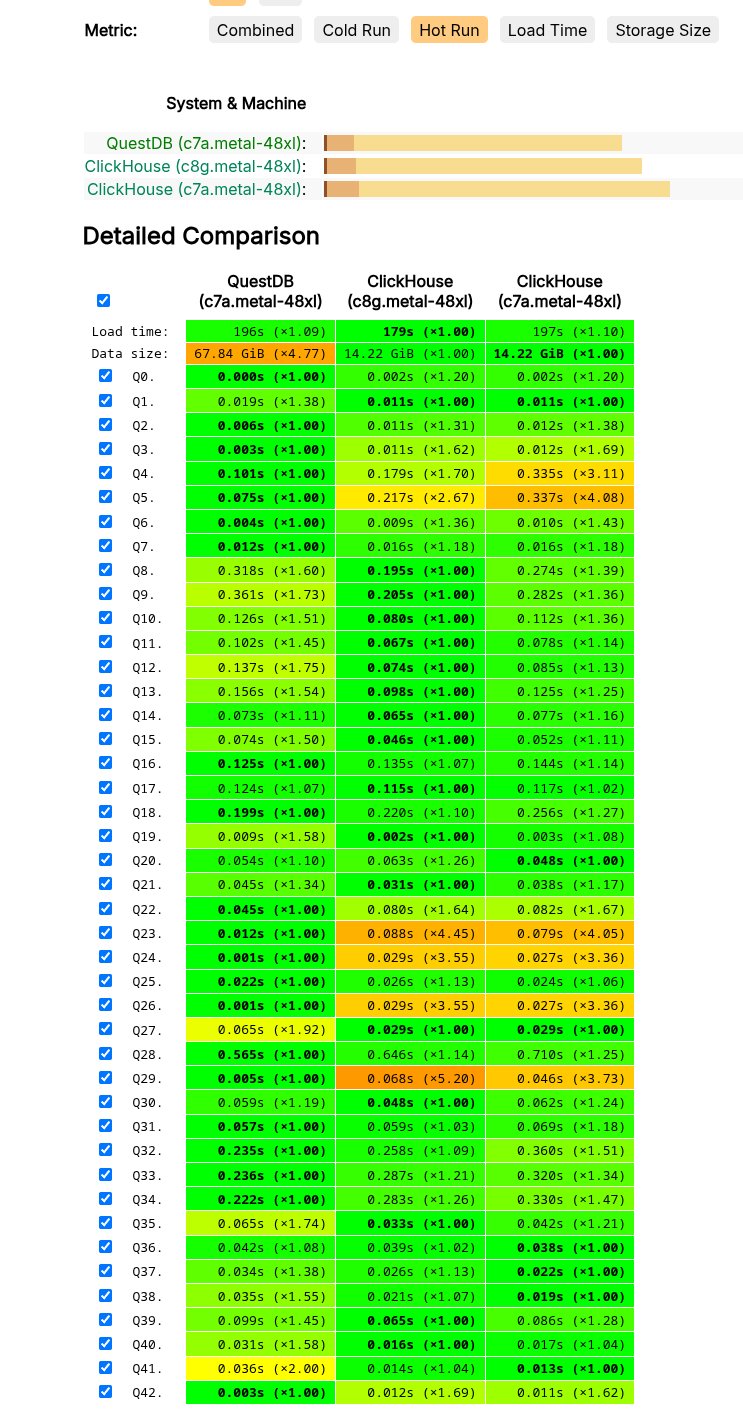
ClickBench: Web analytics workload
ClickBench is a benchmark maintained by ClickHouse that tests analytical query performance on web analytics data (hits from Yandex.Metrica). This is a different workload than TSBS and plays to ClickHouse's strengths: wide tables and string-heavy analytics.
Hardware: QuestDB on AWS c7a.metal-48xl, ClickHouse on both c8g.metal-48xl and c7a.metal-48xl
The results below show hot run performance, where data is already cached in memory. Note that the default view on the ClickBench website shows combined results. Select "Hot Run" to see this view.
Architecture
How data is stored
ClickHouse uses the MergeTree engine. Data is written to immutable parts (one compressed file per column + sparse index), which are continuously merged in the background. You define the sort order via ORDER BY, and rows within each part are physically sorted by that key.
CREATE TABLE trades (timestamp DateTime64(6),symbol String,exchange String,side String,price Float64,quantity Float64,trade_id UInt64) ENGINE = MergeTree()ORDER BY (symbol, timestamp);
QuestDB uses a three-tier architecture: a write-ahead log (WAL) for durability and out-of-order handling, time-partitioned columnar files for query performance, and optional Parquet cold storage on S3/Azure/GCS. No background merges needed.
CREATE TABLE trades (timestamp TIMESTAMP,symbol SYMBOL,exchange SYMBOL,side SYMBOL,price DOUBLE,quantity DOUBLE,trade_id LONG) TIMESTAMP(timestamp) PARTITION BY DAY;
Tier One: Hot ingest (WAL), durable by default
Incoming data is appended to the write-ahead log (WAL) with ultra-low latency. Writes are made durable before any processing, preserving order and surviving failures without data loss. The WAL is asynchronously shipped to object storage, so new replicas can bootstrap quickly and read the same history.
Tier Two: Real-time SQL on live data
Data is time-ordered and de-duplicated into QuestDB's native, time-partitioned columnar format and becomes immediately queryable. Power real-time analysis with vectorized, multi-core execution, streaming materialized views, and time-series SQL (e.g., ASOF JOIN, SAMPLE BY). The query planner spans tiers seamlessly.
Tier Three: Cold storage, open and queryable
Older data is automatically tiered to object storage in Apache Parquet. Query it in-place through QuestDB or use any tool that reads Parquet. This delivers predictable costs, interoperability with AI/ML tooling, and zero lock-in.
The key difference: ClickHouse's MergeTree requires background merges to consolidate parts, which compete with queries for resources. QuestDB's WAL writes directly to time-partitioned columnar storage, giving predictable write latency even under heavy load.
SQL and ecosystem
Both use SQL. ClickHouse has its own dialect; QuestDB extends standard SQL with time-series primitives. Here are two examples of QuestDB queries:
-- Hourly OHLCV bars for yesterdaySELECT timestamp, symbol, sum(quantity) AS volume, avg(price) AS avg_priceFROM tradesWHERE timestamp IN '$yesterday'SAMPLE BY 1h;-- Markout analysis: mid-price evolution-- at 1s, 5s, 30s, 1m, 5m after each tradeSELECT t.symbol, h.offset, avg(q.mid - t.price) AS markoutFROM trades tHORIZON JOIN quotes q ON (t.symbol = q.symbol)LIST (1s, 5s, 30s, 1m, 5m) AS hWHERE t.timestamp IN '$today#XNYS'GROUP BY t.symbol, h.offset;
| QuestDB Extension | Purpose | Example |
|---|---|---|
SAMPLE BY | Time-based aggregation | SELECT avg(price) FROM trades SAMPLE BY 1h |
LATEST ON | Last value per group | SELECT * FROM trades LATEST ON timestamp PARTITION BY symbol |
ASOF JOIN | Time-aligned joins | Join trades with quotes at nearest timestamps |
WINDOW JOIN | Rolling aggregation over time windows | Compute rolling stats from a related table within a time range around each row |
HORIZON JOIN | Multi-offset markout analysis | Measure price evolution at multiple time offsets after each trade in a single pass |
TICK syntax | Declarative timestamp filtering | WHERE ts IN '2025-01-[01..31]#XNYS;6h30m' |
Both databases have broad ecosystem support (Grafana, Kafka, all major client libraries, dbt). QuestDB speaks the PostgreSQL wire protocol, so any PG client library works out of the box. ClickHouse has a more mature ecosystem with a wider variety of table engines and community tooling.
Openness and data formats
QuestDB writes cold data to Apache Parquet on S3, Azure Blob, or GCS. Any tool that reads Parquet (DuckDB, Spark, Trino, pandas) can query it directly, with no QuestDB instance required. Your data stays yours in open formats, queryable across tiers.
ClickHouse stores all data in its proprietary MergeTree columnar format, including cold storage on S3. When ClickHouse tiers data to object storage, it remains in MergeTree format, not Parquet or any other open standard. That data is opaque to everything except ClickHouse. To export it, you need a running ClickHouse instance to do the conversion. It's also worth noting that ClickHouse's cloud-native engine (SharedMergeTree) is closed-source and only available on ClickHouse Cloud, widening the gap between the open-source and proprietary versions.
ClickHouse limitations
Not optimized for streaming ingestion and low-latency queries
ClickHouse is built for batch loading. Streaming single rows or small batches is not where it shines, and the MergeTree architecture adds overhead: incoming data creates small immutable parts that must be merged in the background, competing with queries for resources. Deduplication in particular has a significant impact on ingest performance compared to QuestDB's WAL-based approach, which handles deduplication natively during the commit phase.
Lacking primitives for time-series analysis
ClickHouse has no equivalent to SAMPLE BY, LATEST ON, WINDOW JOIN, HORIZON JOIN, or TICK syntax. Some of these can be approximated with verbose workarounds (explicit GROUP BY toStartOfInterval(...), subqueries, self-joins), but others like multi-offset markout analysis with HORIZON JOIN are simply not possible in ClickHouse.
Even where workarounds exist, performance is the real gap. QuestDB's ASOF JOIN uses six different algorithms under the hood and selects the optimal one based on data distribution. HORIZON JOIN computes markout analysis at multiple time offsets in a single pass. LATEST ON completes in 1.56ms where ClickHouse needs 41ms (27x slower). These are not ergonomic differences; they are performance differences on the workloads that matter for capital markets and real-time analytics.
Hard to operate at scale
ClickHouse's MergeTree architecture requires careful tuning: part management (the default limit of 300 parts per partition requires monitoring), merge scheduling (background merges compete with queries for CPU), and ORDER BY selection (choosing the wrong primary key order significantly impacts performance, and changing it means recreating the table). ClickHouse Cloud addresses this with a fully managed offering, but self-hosted ClickHouse remains operationally demanding.
QuestDB limitations
Narrower scope by design
QuestDB is purpose-built for time-series and financial data workloads. If you need a general-purpose OLAP engine for product analytics, log search, or ad-hoc BI across semi-structured data, ClickHouse covers more ground.
Younger ecosystem
ClickHouse has been open-source since 2016, QuestDB since 2019. That three-year head start shows in the number of third-party integrations, community tooling, and resources available.
Conclusion
Choose QuestDB where speed is mission critical. Capital markets, trading, crypto, defense, energy, and robotics teams choose QuestDB for streaming ingestion, low-latency queries, and time-series SQL primitives. Data flows in fast and flows out to an open lakehouse (Parquet on S3) with no lock-in.
Choose ClickHouse for observability (logs, traces, metrics), product analytics, semi-structured JSON data, or general OLAP workloads where you want a managed cloud service and a broad ecosystem.
Ready to try QuestDB? Get started with the quickstart guide or join our Slack community to ask questions.