Why AI needs a database
AI-powered language models have arrived. The hype storm is real. Suddenly, frontier models are the hammer and every opportunity looks like a nail.
But is this really the case? Will an AI solve all of our infrastructure and development challenges? Nope - not yet, anyways. That said, their intelligent use will supercharge our capabilties and require broad adaptation.
In this article, we'll pierce through the confusion and wild claims, and better define the dynamic and profound agentified era of database + AI collaboration.
To that tune, we'll consider a question:
Will an AI replace my database?
To answer that, we'll start with the token problem.

The token problem
A token is the smallest unit of text a language model processes, typically a word, subword, or even a character, depending on the tokenizer. Models don't read text like humans do — they break text into tokens, which serve as the building blocks for understanding and generating language.
Let's demonstrate simplified tokenization on a context-rich sentence:

This whole sentence is 6 tokens.
It's a tidy process. But what about information that isn't text?
Structured data doesn't tokenize well — LLMs stumble over it.
To illustrate the point, let's "tokenize" a structured timestamp:

That's 17 tokens, depending on the tokenizer - ChatGPT-4o pictured.
Converted into a microsecond timestamp - 1646762637609765 - it's 7.
Either way, that's a lot of tokens for a single, precise point of data.
Databases - especially time-series databases - are stuffed with structured data.
Consider a database table full of financial trades.
We have one such database on our demo instance:
SELECT * FROM trades;
This table has over 1.5 billion rows representing various trades across time.
As an uncompressed file it's "only" 52GB - pretty lean, right?
But how many tokens do you think are contained in that 52GB?
Tokenizing, War and Peace
Textual data is naturally broken into words and phrases that align with an LLM's tokenization scheme. Structured datasets - tables, logs, financial records, and similar - are highly compressed formats that become wildly inefficient when converted into LLM-readable sequences.
Consider one row from our trades table:
| symbol | side | price | amount | timestamp |
|---|---|---|---|---|
ETH-USD | sell | 2615.54 | 0.00044 | 2022-03-08T18:03:57... |
How many tokens do you think make up this one row?
| Value | Estimated tokens |
|---|---|
ETH-USD | ~2 tokens |
sell | ~1 token |
2615.54 | ~4+ tokens |
0.00044 | ~3+ tokens |
2022-03-08T18:03:57.609765Z | ~16+ tokens |
Before metadata or padding, one row balloons to 25-30 tokens.
Within this range, let's estimate the total token size of the dataset...
-
Lower bound: 1.5 billion rows * 25 avg tokens = 37.5 billion tokens
-
Upper bound: 1.5 billion rows * 30 avg tokens = 45 billion tokens
For reference, GPT-3 took ~300 billion tokens to train. The training set included a significant portion of the organized English that we've digitized: encyclopedias, articles, websites, books, and much, much more. This is hundreds of terabytes of information.
Our relatively tiny 52GB example dataset of 1.5 billion rows would have consumed ~15% of GPT-3's entire training budget if tokenized!
Most structured datasets are much larger than 52GB. Billions of rows in a real financial dataset wouldn't be a few gigabytes — it would be hundreds, terabytes even, and it would expand through a constant, real-time stream. Token counts for a useful timeframe would skyrocket into the trillions. Wild.
As such, "training" on this data would be:
- Wildly expensive
- Very, very slow
- Deeply impractical
Why's that? How does that work?
Unforgiving tokenomics
LLMs tokenize data based on learned language structures.
Structured and binary data do not map efficiently to these token vocabularies.
This results in severe token expansion when converting structured datasets:
| Data type | Bytes per token | Tokens per 1GB | Expansion vs. text |
|---|---|---|---|
| Plain Text | ~4 bytes/token | 250M tokens | 1× (baseline) |
| JSON Data | ~2-3 bytes/token | 500M-750M tokens | 2-3× |
| Tabular Data | ~1-2 bytes/token | 865M-1B tokens | 3.5-4× |
| Binary Logs | ~0.75-1.5 bytes/token | 670M-1.3B tokens | 3-5× |
Tokenization is lossy and inefficient for structured data.
It breaks information into approximate units optimized for prediction, not retrieval. This expansive process is especially dramatic for numerical and binary data, where precise values must be split across multiple tokens.
Consider this:
For text data, 1GB of data is 1800 novels of average length.
That's about 286 copies of War and Peace.
This expands into about 250M tokens.
For structured data, 1GB is ~29 million rows of transactions over mere weeks.
This expands into almost a billion tokens — almost 4× the size of plain text.
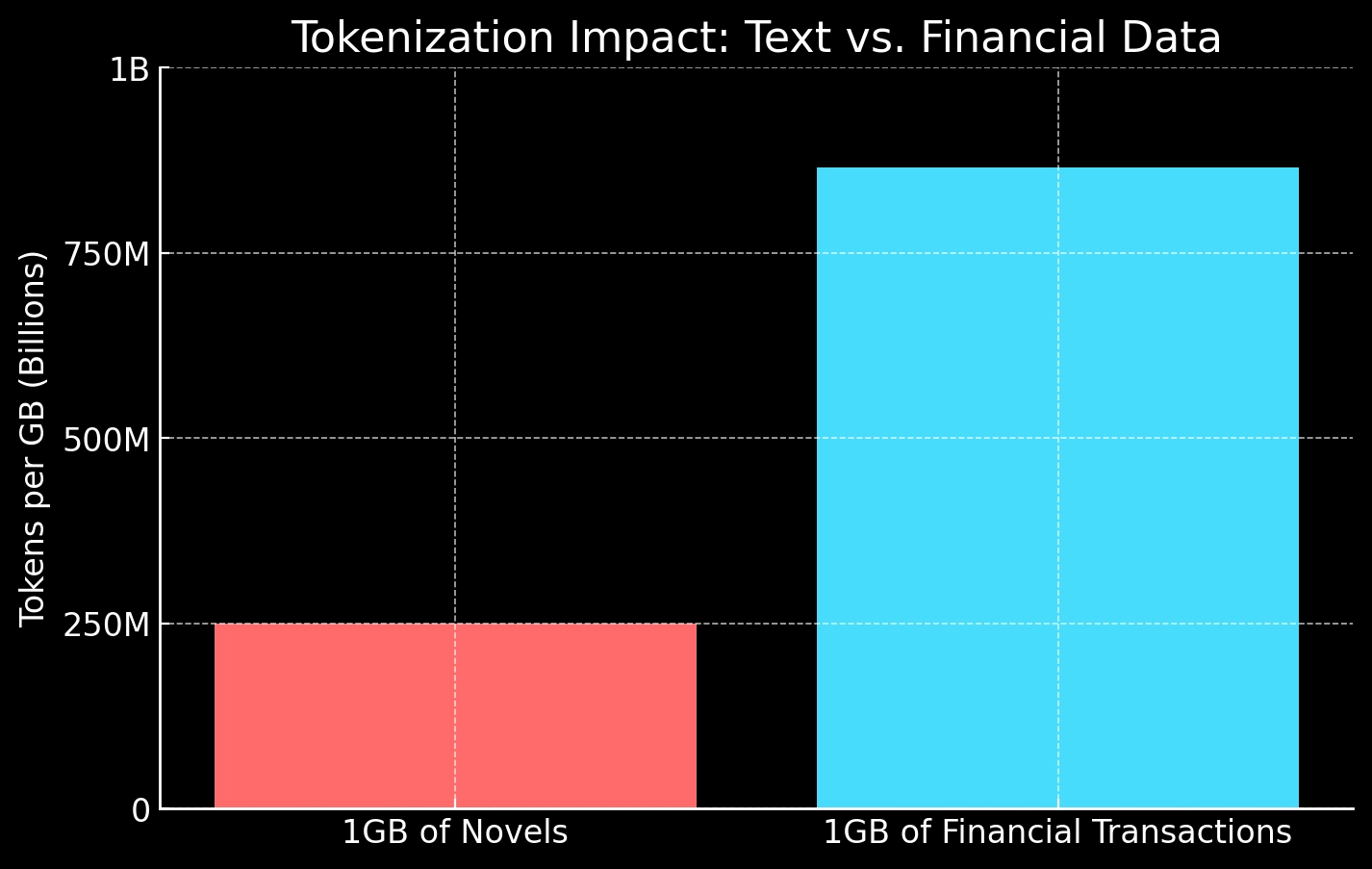
A single month of financial data outstrips entire bookshelves of classic literature. But, eh, the financial dataset still seems so small.
Can't the LLM just store it for us and analyze its contents?
Training ≠ storing
If LLMs simply "memorized" everything, they'd function like a lossless compression algorithm, perfectly retrieving exact details on demand.
But as shown above with tokenizing, we see the opposite.
As a result:
- LLMs struggle with factual recall
- They generate responses probabilistically
- They approximate facts, rather than retrieve exact data
Why? A model is a function, not a repository.
If 300 billion tokens were stored directly, you'd expect something many terabytes in size. But it's lossily compressed from data, into tokens, then into parameterized weights during training. Millions of words become billions of tokens which become just hundreds of gigabytes of weights.
This is possible because a model doesn't store text, it learns patterns.
It forms an intricate map of probabilities and relationships.
This creates an abstraction atop meaning, not a ledger of exact records.
In this sense, training is less like taking a snapshot of reality and more like sculpting a shape out of raw material — only the most "statistically useful" features remain. Statistically useful is... OK, but is it accurate?

Trying to extract precise information from a model — like the exact closing price of Ethereum on a specific date — is a fundamentally misaligned request.
An LLM might generate a plausible answer, but there's no guarantee it's correct. This presents a major challenge. Structured datasets — prices, transactions, and events — constantly change. Today's models can't keep up.
So why can't we just "give our data to the model", in CSV chunks if we have to, to produce insights from it and "talk to it" in real-time? Can't we use a pre-prompt, Retrieval-Augmented Generation (RAG), or "context"?
"Just AI it"
In other words: can't we "just AI it" anyway?
Nope. Not if we expect accuracy, quality and recency from our results.
Unfortunately, LLMs just don't work that way.

The problem is, context windows are fixed, and structured data is massive.
Even state-of-the-art models like Claude 3.7 max out at 200K tokens per conversation. While this might seem large, it's only a tiny fraction of a real structured dataset.
A common assumption is that chunking — splitting a dataset into smaller parts and feeding them incrementally — allows an LLM to work with large-scale structured data.
The bottleneck remains the model's ability to retain past data. LLMs do not have persistent memory; they process only what is inside their active context window.
Each new chunk overwrites earlier chunks once the context limit is reached, meaning older data is forgotten. Unlike a database, which indexes and retains all historical records, an LLM's memory resets every time it reaches capacity.
| Model | Parameters | Context window size (tokens) |
|---|---|---|
| GPT-4 Turbo | 1.76 trillion* | 128,000 |
| Claude 3 | 540 billion | 200,000 (expandable to 1 million) |
| Claude 3.5 Sonnet | Not specified | 200,000 |
| Claude 3.5 Haiku | Not specified | 200,000 |
| Claude 3.7 Sonnet | Not specified | 200,000 |
| DeepSeek-V2 | 236 billion | 128,000 |
| DeepSeek-V3 | 671 billion | 128,000 |
| Jamba | 52 billion | 256,000 |
Even if we manage to fit a portion of the dataset into a prompt, LLMs do not retrieve facts deterministically — they generate responses probabilistically. This means even when given the same correct data, an LLM might:
- Return slightly different numbers
- Round off values inconsistently
- Introduce hallucinated data
So, what do we do?
Enter the trusty database.
Database: friend of AI
Databases, on the other hand, provide:
- Exact lookup, deterministic access to structured data
- Real-time updates, new data is immediately available
- Precision, answers are exact, not probabilistic estimates
The solution isn't to replace databases but to integrate them into AI workflows. Instead of forcing AI models to "remember" everything, we give them access to query and interpret structured data dynamically.

AIs, like able humans, apes and mischievous crows, can work with tools.
This has powerful potential, especially when we consider high-tier data like that within financial markets, industrial metrics, and sensor data, all which stream in real-time and at enormous scale.
These datasets are often:
- Massive, with billions of rows and terabytes of data
- Think of the tokens!
- High-frequency, expanding every millisecond
- High-cardinality, with thousands of unique entities
So what if an AI directly calls a database - QuestDB, PostgreSQL, or similar?
-
The model translates natural language into structured SQL queries
-
The database executes the query, and the model interprets the results
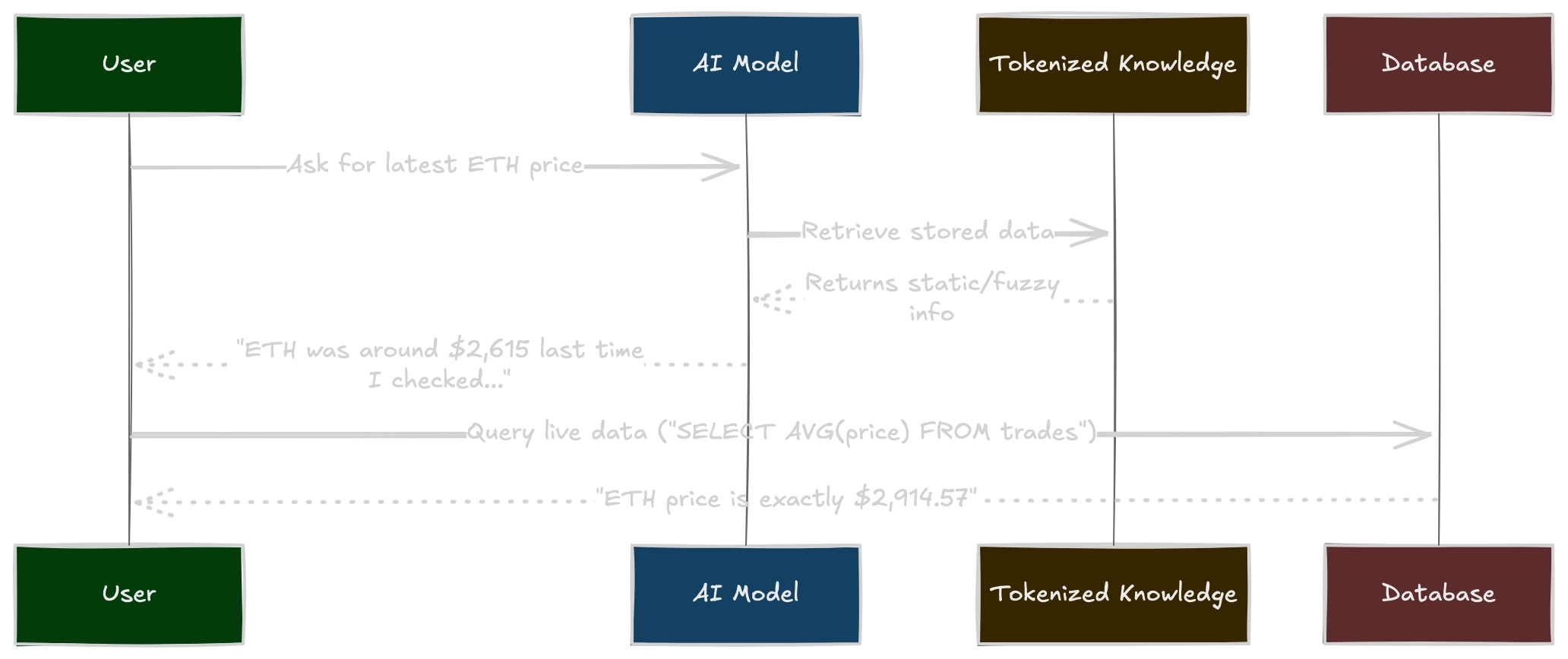
This provides exact numerical recall, with no approximations.
It's live, up-to-date data retrieval, which scales efficiently for massive datasets.
In theory, it solves the token problem.
The model won't be crushed by the token bloat of unstructured data.
But how does this work in real-world "AI" systems?
Direct database querying
Let's say an AI-powered trading assistant needs to analyze market trends and explain them to a human. Instead of making the AI model "memorize" past trades, we let it dynamically query something like QuestDB.
User asks an "agent" or similar model-guided entry point:
"How did ETH perform last month compared to BTC?"
As of today, frontier models are proficient at query generation when they know the available syntax. With a coherent pre-prompt, the AI then converts to SQL:
SELECT symbol, AVG(price) FROM tradesWHERE timestamp BETWEEN '2022-03-01' AND '2022-03-31'GROUP BY symbol;
QuestDB then executes in milliseconds, returning exact averages:
| symbol | AVG Price |
|---|---|
| ETH-USD | 2914.567413002606 |
| BTC-USD | 42180.825850850815 |
The model then interprets them: "ETH's average price was $2,914.57, whereas BTC's was $42,180.83. This suggests ETH had lower volatility in March."
By separating the logic, we achieve accuracy and sub-second response times instead of janky LLM-generated estimates or a ponderous journey through a large index. We receive exact data, instead of probabilistic inference.
In this hybrid approach, QuestDB ingests a massive stream of data, scaling cost-effectively as it routes data from immediate storage into less expensive object storage for historical querying.
Both the latest information and historical data are thus always available for immediate analysis. The cost of storing this data, the relative simplicity of the entry point (one query into all your historical data), and the millisecond response time, offer extreme efficiency and performance.

With database access and a clean pre-prompt, a conversational interface atop one source which contains "all of your data over time" turns the model into something profound. Given its vast knowledge about market analysis techniques, these conversations generate queries and visualizations that are extremely deep, precise, up-to-date, and fast.
A clean system-of-record at scale provides a simplified interface for your AI or agent to use. It's also easily verifiable against the source, with SQL being as coherent for a human as it is for an agent. The best of both worlds.
The bottleneck in how fluid these conversations will feel - and in how "far back" in time that they can go - is the quality of the data store and the query engine underneath. Overly complicated and expensive ingress/egress architectures will slow things down and weaken response quality.
Choose your AI's partner carefully!

The Others
So, what are our other options?
If we are working with structured data, are there other techniques?

Embedding & vectorized search
Vector search converts text into embeddings — lists of numbers which capture meaning in a mathematical space. Similar meanings have similar vectors, even if they use different words.
When a query is made, an approximate nearest-neighbor (ANN) search finds the most semantically similar data points. These data points then return as standalone search results, or are re-routed into an LLM as additional context.

This method is fast for unstructured text, making it ideal for:
- Research papers
- Customer support logs
- Knowledge bases
Given that embeddings are indexed, there's no need to retrain the model.
We just update the search index.
As such, vector search excels at unstructured data retrieval.
But it struggles with exact values and real-time updates.
Why?
- Embeddings rank similarity over precision - a price of $99.99 vs. $100.01 may be similar in value but far apart in embedding space
- Precomputed embeddings can become outdated - if financial transactions change, old embeddings remain static
Typically, vector search on its own doesn't generate new content — it retrieves the closest matching results. When we add generation into the flow, then we're talking about RAG.
Retrieval-Augmented Generation (RAG)
RAG builds on vector search.
Instead of relying on the model's internal knowledge, RAG retrieves up-to-date information from an external source — typically a "vector-friendly" database like Pinecone, Weaviate, or Elasticsearch. The LLM then combines the original query with the retrieved data to generate an answer.

This method is particularly powerful because it:
- Allows real-time updates
- Expands an LLM's effective knowledge without retraining
- Bridges structured and unstructured retrieval, making it flexible
RAG retrieves and integrates external data. As such, it too excels with the same dynamic, knowledge-heavy applications as its forebearer.
However, RAG still inherits the weaknesses of vector search when it comes to structured numerical data. It does not guarantee exact numerical recall, meaning financial or time-series data isn't a strong fit.
The approach also leans quite heavily on a well-structured retrieval pipeline. Poor retrieval pipelines mean poor results. Query efficiency also depends on the search index quality and can degrade performance if unkempt.
Furthermore, multi-step retrieval methodologies introduce latency before response generation. This is crucial when you expect a fluid and information-rich conversation.
If accuracy, deterministic values, recency, and fluid speed are needed, such as within financial data, real-time analytics, structured logs, and IoT, then direct database querying is the best choice for unstructured data.
Summary
A language model is not a database, nor should it be treated as one.
Depending on your data-type, the best approach is to combine AI's language capabilities with something else, like a high-performance database which can scale and simplify the overall ingest and query architecture atop your data.
This enables real-time, accurate, and cost-effective conversations, and avoids the pitfalls of tokenization overload, slow retrieval, and hallucinated responses.
In sum, an AI isn't coming to replace your database. It needs its help.
... For now...
