We finally benchmarked InfluxDB 3 OSS Core (Alpha)
Editor’s note: This article was written during the InfluxDB 3 alpha phase. InfluxDB 3 is now generally available. For up-to-date benchmarks and performance comparisons against QuestDB, see our latest InfluxDB 3 Core benchmark.
InfluxDB 3 released as a Cloud-only product in April 2023. Along with the release, the team announced their plans to release an open source version. It was billed as having 100x faster queries, 10x faster ingestion performance, and 10x better compression. The community was enthusiastic, especially for the release of the open source version.
At long last, in January 2025, InfluxDB 3 Core Alpha finally released. The release blog post states it is "a high-performance recent-data engine". This is a slight deviation from the usual "time-series database" descriptor, and we'll unpack precisely why.
But before we get too deep, we should mention that InfluxData states that version 3 is Alpha and not production-ready. Given it's working in their cloud, and that we didn't want to wait for a stable version to get a ballpark of its performance, we decided to offer an early look.
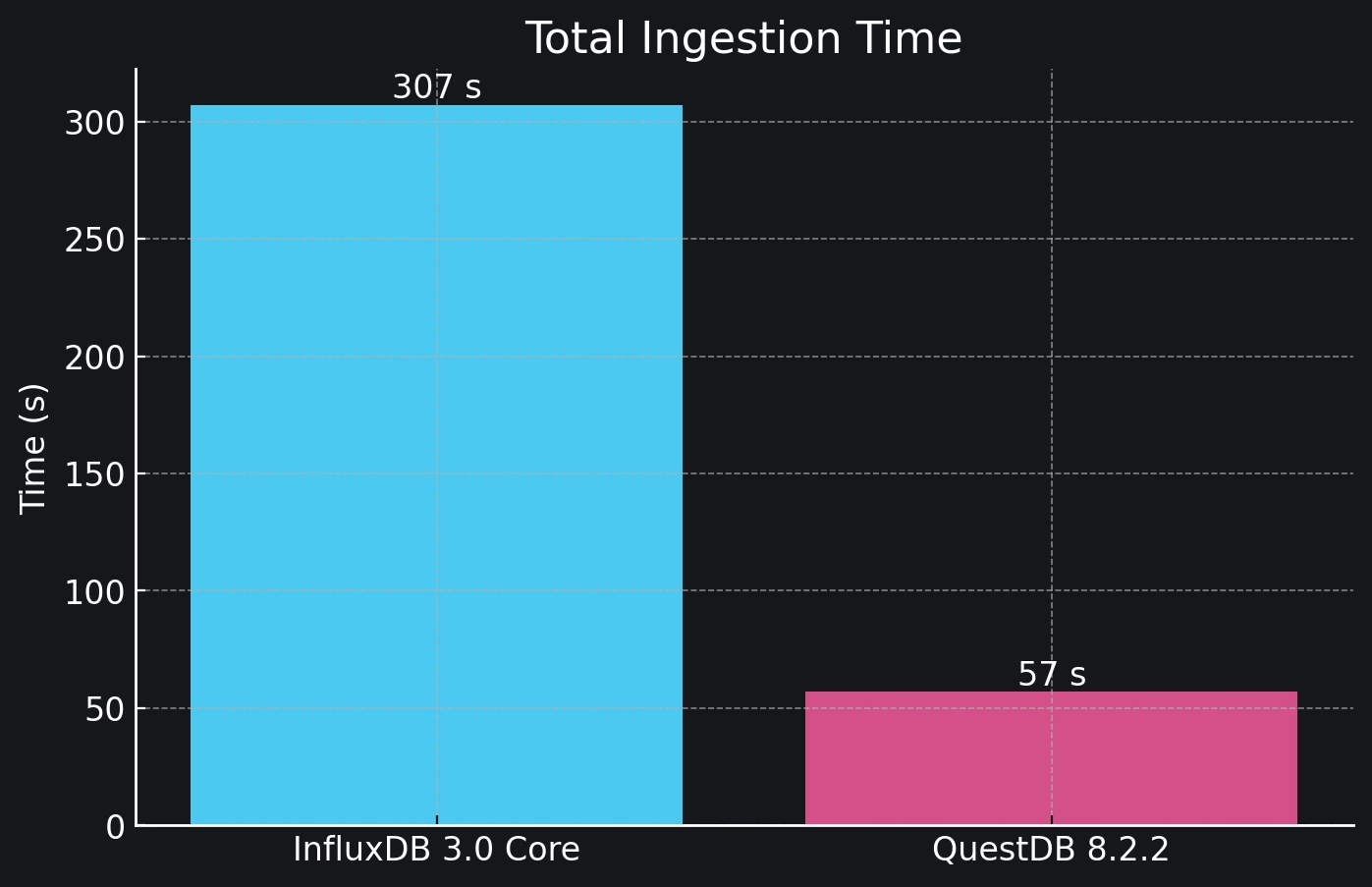
In our testing, we found that InfluxDB 3.0 Core ingested data approximately 5.5 times slower than QuestDB 8.2.2.
We'll unpack the results and examine potential trade-offs.
Disclaimer: These tests were conducted using a custom Python script in a controlled AWS environment. They are intended to provide a ballpark performance estimate rather than an exhaustive evaluation. Your mileage may vary.
Speaking of trade-offs
There is a big one off the top, and it's hinted at by the label "recent-data engine". With InfluxDB 3 Core, you can store as much data as you want. But a single query may only cover a maximum time span of 72 hours. This is a pretty big departure from the usual behaviour of querying within the time-range of the data set.
So, for now, we'll focus primarily on ingestion. When the querying side of InfluxDB 3 Core settles down in later versions, we'll revisit the topic.
Setting up the benchmark
Benchmark time.
We'll boot up an m6a.4xlarge (16 vCPUS) with a gp3 EBS drive on AWS, and clone our fork of
the TSBS benchmark. For those unfamiliar, this is a benchmark suite
specialized for time-series and originally developed by InfluxData to benchmark InfluxDB.
Benchmarking between QuestDB and InfluxDB is straightforward and provides solid grounds for competition, as QuestDB natively supports the Influx Line Protocol (ILP) for ingestion. It's truly an apples-to-apples comparison; both are time-series databases which consume ILP-shaped data points.
To generate a dataset of ILP points, we:
~/tmp/go/bin/tsbs_generate_data \--use-case="cpu-only" --seed=123 --scale=4000 \--timestamp-start="2016-01-01T00:00:00Z" --timestamp-end="2016-01-02T00:00:00Z" \--log-interval="10s" --format="influx" > /tmp/data
This command generates roughly 34.5 million rows of ILP data within a 12GB text file. It represents 4000 servers sending a row of data every 10 seconds for 24 hours. Every row contains 21 columns: a timestamp, 10 dimensions, and 10 metrics.
It's considered high cardinality as the number of unique tags (think, symbol values) is high. This is an area where InfluxDB 2 and earlier versions struggled, and many hoped v3 would improve upon it.
This is an extract of the file:
cpu,hostname=host_0,region=eu-central-1,datacenter=eu-central-1a,rack=6,os=Ubuntu15.10,arch=x86,team=SF,service=19,service_version=1,service_environment=test usage_user=58i,usage_system=2i,usage_idle=24i,usage_nice=61i,usage_iowait=22i,usage_irq=63i,usage_softirq=6i,usage_steal=44i,usage_guest=80i,usage_guest_nice=38i 1451606400000000000cpu,hostname=host_1,region=us-west-1,datacenter=us-west-1a,rack=41,os=Ubuntu15.10,arch=x64,team=NYC,service=9,service_version=1,service_environment=staging usage_user=84i,usage_system=11i,usage_idle=53i,usage_nice=87i,usage_iowait=29i,usage_irq=20i,usage_softirq=54i,usage_steal=77i,usage_guest=53i,usage_guest_nice=74i 1451606400000000000cpu,hostname=host_2,region=sa-east-1,datacenter=sa-east-1a,rack=89,os=Ubuntu16.04LTS,arch=x86,team=LON,service=13,service_version=0,service_environment=staging usage_user=29i,usage_system=48i,usage_idle=5i,usage_nice=63i,usage_iowait=17i,usage_irq=52i,usage_softirq=60i,usage_steal=49i,usage_guest=93i,usage_guest_nice=1i 1451606400000000000cpu,hostname=host_3,region=us-west-2,datacenter=us-west-2b,rack=12,os=Ubuntu15.10,arch=x64,team=CHI,service=18,service_version=1,service_environment=production usage_user=8i,usage_system=21i,usage_idle=89i,usage_nice=78i,usage_iowait=30i,usage_irq=81i,usage_softirq=33i,usage_steal=24i,usage_guest=24i,usage_guest_nice=82i 1451606400000000000
For those unfamiliar with the ILP format, the first item is the table name (cpu), and the last item is the timestamp in nanoseconds. The rest of the items are columns. Or, in InfluxDB-terms, they are named tags and fields. But you can think of them as columns on a table.
And... go! Then stop
On our first benchmark attempt, we ran into issues with the TSBS ingestion load script. Originally built for InfluxDB 1.0 and later adapted for Influx 2.0, the tool encountered metadata issues when pointed at InfluxDB 3.0.
After tweaking the code, we realized that the required changes weren't trivial. We were keen to get going, so after deliberating we decided to use a simple Python script to perform ingestion. While not a strictly scientific benchmark, it closely mimics real-world data ingestion scenarios.
The Python script is available on GitHub.
It works by reading the data file line by line, grouping rows into chunks of 30,000, and then sending these chunks in parallel using four (configurable) worker threads. The chunk size was chosen after some experimentation, as larger chunks caused InfluxDB to return a "post too large" error.
All told, we measure both the wall-clock time, and the aggregated duration for all the HTTP requests. For the benchmark we ingested ~34.5 million rows, but in the repository there is a smaller data file (~2.1 million rows), due to github file size limitations.
So, in summary, we used the following setup:
- Dataset: Approximately 34.5 million rows of Influx Line Protocol data (generated by TSBS benchmark).
- Ingestion Method: A custom Python script that sends data in 30,000-row chunks concurrently using 4 workers
- Hardware: AWS
m6a.4xlarge(16 vCPUS) with a gp3 EBS drive
Results
InfluxDB 3.0 Core:
Started InfluxDB with the default config:
influxdb3 serve --node-id=local01 --object-store=file --data-dir .influxdb/data/node0/ --http-bind=0.0.0.0:8181
Started the test with:
python3 send_in_chunks.py --host=http://127.0.0.1:8181 --file=/tmp/data --chunk-size=30000 --workers=4 --backend=influxdb
Cleaned up with:
influxdb3 delete database sensors
Note the clean up command - can you spot what's unusual?
We'll show you a little later.
For Comparison – QuestDB 8.2.2
Started QuestDB with default config:
./questdb.sh start -d ~/questdb_root
Started the test with:
python3 send_in_chunks.py --host=http://127.0.0.1:9000 --file=/tmp/data --chunk-size=30000 --workers=4 --backend=questdb
Cleaned up with:
DROP TABLE cpu
Resulting speeds
| Metric | InfluxDB 3.0 Core | QuestDB 8.2.2 |
|---|---|---|
| Per-chunk ingestion time (30k rows) | 600-1200 ms | 70-150 ms |
| Total ingestion time | 307 seconds | 57 seconds |
SELECT COUNT(*) FROM cpu | 48 seconds | 0.0005 seconds |
In the end, InfluxDB 3 Core ingested ~5.5x slower than QuestDB. Even if we were not specifically running the benchmark
for queries, we were surprised to see the time it took to run a simple count query.
After multiple tests with different chunk sizes and a search through the current InfluxDB 3 Core documentation, we were unable to find clear instructions on how to further tune for better performance.
We typically use default settings for fair benchmarking, but we also wanted to explore its performance when tuned. To our surprise, even using the --object-store=memory option, which according to the docs should not persist any data, we did not see a significant improvement in performance.
Alpha is alpha
Apart from performance, in its current state, the product is indeed Alpha and not fit for production.
In fairness, this was clearly stated by the InfluxData team.
That said, several issues surfaced during ingestion with InfluxDB 3.0 Core:
Parallel table creation errors and data loss
Our script sends chunks in parallel. Unfortunately, this led to errors: Error: catalog update error: table 'cpu' already exists.
More critically, over 1 million rows were lost due to these errors.
When executing the script with a single worker, it didn't lose any rows. But this is a less realistic scenario. It also took a whopping 18 minutes to complete. For comparison, it took QuestDB 120 seconds to ingest from a single worker, ~9x faster than InfluxDB 3 Core.
Database startup time
When empty, the database starts immediately. But after data ingestion, a restart took 56.83 seconds while displaying messages about replaying WAL files.
We also observed that, if we stopped the database and then restarted several minutes later, it would start replaying WAL files and then show a "Killed" message with no extra info after a few seconds. We couldn't find a workaround to restart other than deleting the database folder.
Command Line Tool Limitations
The CLI tools provided with InfluxDB 3.0 Core Alpha have a long way to go. For example, the influxdb3 write command
complains about the POST size with a file of only 3000 ILP lines, while the Python script could send up to 10 times
more on each chunk before the server complained.
The influxdb3 query does not allow the user to provide a host/port different to the default, so if you want to query a
server other than http://localhost:8181 you need to use an official client or Apache Arrow.
We also found that querying the API directly using curl —- as in their documented examples —- often failed with curl: (18) transfer closed with outstanding read data remaining.
The same API call done directly from the browser returned net::ERR_INCOMPLETE_CHUNKED_ENCODING 200 (OK). We reported
this on github, and hopefully it will be fixed.
The forever database
Now let's get back to that clean up command: influxdb3 delete database sensors.
You can create or delete a database from the command line, and tables are auto-created. Unfortunately, we couldn't find a way to drop a single table. The only apparent solution was to drop the whole database, which is seldom ideal.
While we are sure all of these issues will be addressed as the product gets from Alpha to stable, there are a few hints we can glean from this experience.
Proud of the Cloud
A hallmark of strong open source software is its ability to stand on its own. Many open source database products thrive in production-heavy environments, long before users ever need to engage with the company behind them. In that sense, the InfluxDB 3 Core Alpha is a curiosity.
Its 72-hour data retention limit and early developer experience suggest that it's not destined to be a fully capable product in its own right, but rather a stepping stone. The message is that to get the full promise of InfluxDB 3, users will need to rely on InfluxData's Cloud offering.
This makes the open source edition feel less like a self-sufficient system and more like a limited trial, nudging the community to start within the commercial experience.
We're not here to pass judgment. After all, we have a commercial offering that builds upon our open source core. But it's worth noting the direction InfluxDB is taking.
InfluxDB's community has been eagerly anticipating an open source release of version 3. For some, it may be time to start searching for an alternative.
Conclusion
InfluxDB Core 3 is in its Alpha stage. It shows promise; the engineering behind InfluxDB 3.0 Core is impressive, with a modernized engine, SQL support, and integration with open formats.
But in its current state, the ingestion performance lags behind alternatives and it loses data under concurrent loads. Plus, queries are limited to a 72-hour window.
If you need an open source database that can ingest data rapidly and handle queries spanning more than 72 hours of data, you may be better off sticking with InfluxDB 2.0 (outdated), or having a look at an alternative.
QuestDB offers strong ingestion speeds and out-of-the-box ILP compatibility. Benchmark the latest version of QuestDB either using the TSBS benchmark, or the ClickBench benchmark, not optimized for time-series, but in which QuestDB also performs fairly well.
To walk through how to replace InfluxDB with QuestDB, check out our tutorial.