Why Parquet Matters for Time Series and Financial Services
Financial data is growing at a pace that is hard to keep up with. Every tick, quote, and trade across multiple exchanges adds up fast. A single day can produce billions of rows, and stretch that across months or years, and you are looking at terabytes of information. Analysts, quants, and data engineers face the same challenge: how do you make sense of all this data as quick as the market needs it?
Open formats provide the answer. Instead of locking your data into one vendor's ecosystem, open standards let it move freely. They simplify integration, reduce storage costs, and make pipelines more flexible. No team wants to be stuck with a rigid system when markets change this quickly.
Among these formats, Parquet stands out. By storing data column by column instead of row by row, Parquet allows you to read only what you need. If your strategy only requires prices and timestamps, you can skip the rest. That means faster queries, lower memory usage, and less unnecessary I/O.
This resonates well with QuestDB, whose mission has always been to provide the fastest time series database. It embraces open formats, hence it naturally comes with Parquet support.
What Makes Parquet Different
Parquet was originally created at Twitter and Cloudera. Today, it is an Apache project and a standard supported by nearly every modern analytics tool, including Spark, Flink, DuckDB, Pandas, and, of course, QuestDB.
As mentioned, Parquet is not a "traditional" row-based data format. Row-based storage is like saving it one row at a time. You grab the whole row, even if you only need a few cells. Columnar storage, such as Parquet or databases like QuestDB, keeps each column together. When only certain data points are needed, you do not touch the rest.
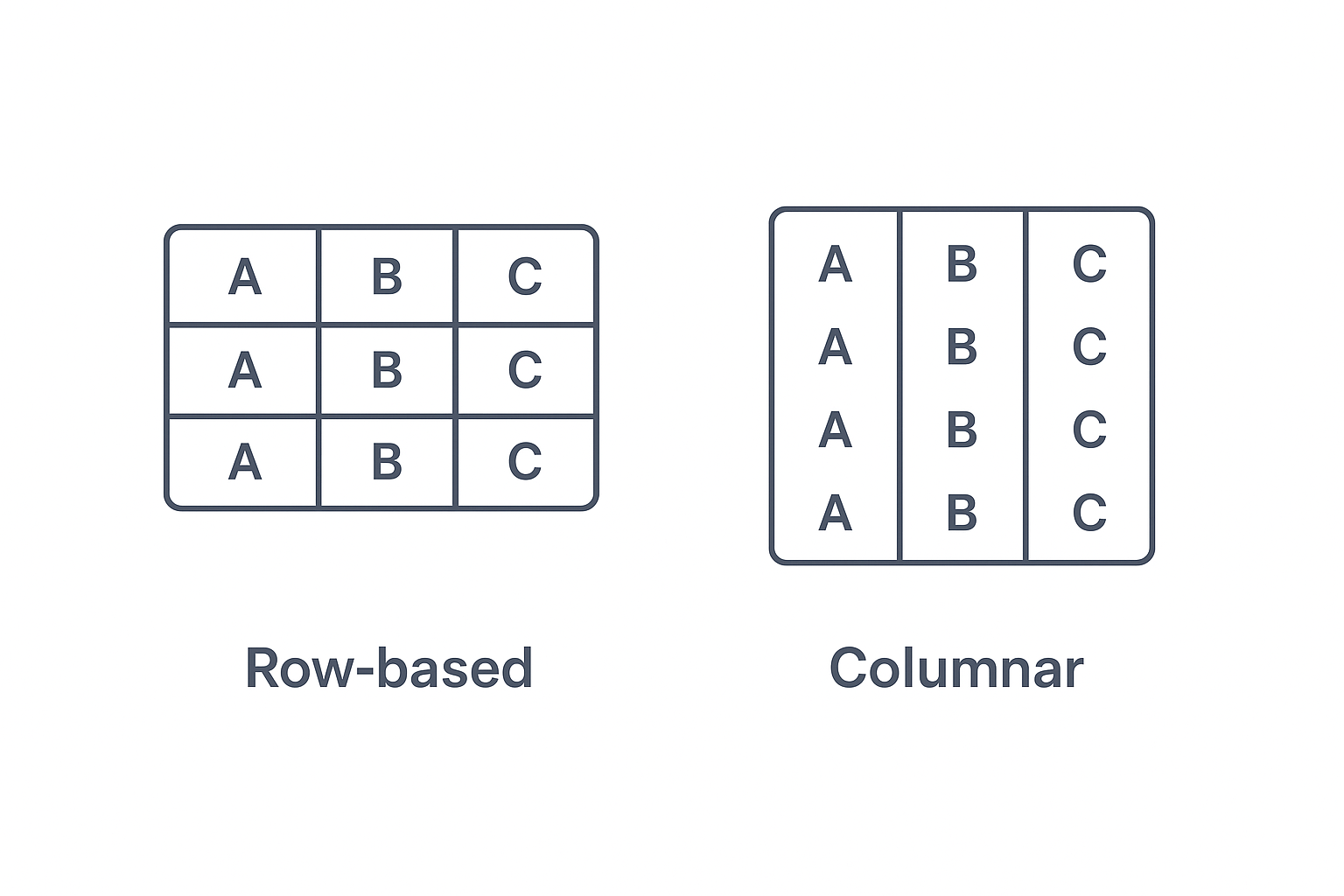
Parquet has become a standard in the data engineering and data science world. Today, it is supported by nearly every modern analytics tool, including Spark, Flink, DuckDB, Pandas, and, unsurprisingly, QuestDB.
Why Parquet Matters for Finance and Market Data
Take S&P futures as an example. About 800 million rows are generated in a single day. In just a few days, it adds up to terabytes of uncompressed data. Storing it is one thing, but making it usable is another.
Parquet simplifies the process. Its column-based compression works especially well for financial data. Repeated fields like exchange IDs, symbols, or order types compress efficiently, and timestamps that shift only slightly make files even smaller. Besides, Parquet supports different encodings (RLE, Dictionary, Delta...) for different columns, which allows for more efficient compression depending on the column type.
Parquet not only lets analysts read just the columns they need, skipping the rest, but also stores metadata that can
completely skip whole chunks of data depending on the values on the WHERE filter. This way, scanning
billions of rows becomes much faster and more efficient. Especially when combined with a database that has native support for working with Parquet. On top of that, Parquet has a rich typing system, supporting structures like arrays, which are also supported by QuestDB and can be particularly useful when storing order book data.
Parquet's status as an open standard is just as important as its performance. Finance teams need to stay agile. Pipelines must adapt as tools evolve, and avoiding vendor lock-in is critical. With Parquet, flexibility comes built in.
Interoperability Across the Analytics and Data Science Ecosystem
Due to its open format, Parquet has become very popular for analytics, as it plays well with many tools. Whether running ad hoc queries in DuckDB, exploring datasets with Pandas or Polars, scaling up distributed processing with Spark, or training ML models, Parquet simply works. Because the schema is stored right in the file, tools can read it without any extra setup.
This broad support makes it easy to combine QuestDB with the rest of your data stack. You might use QuestDB to ingest and store raw time series data at high speed, then convert historical partitions to Parquet for downstream analysis. A quant could read those files from Pandas to prototype a strategy, while a data engineering team processes the same files in Spark to build aggregates. Parquet acts as the bridge between real-time workloads in QuestDB and offline workflows across the broader ecosystem.
Parquet also fits naturally into architectures where storage and compute are separate. Data can be stored in object storage like S3 or GCS, and multiple engines can query the same files without copying them around.
In practice, this means financial datasets written once in Parquet can be reused throughout the stack. From time series analysis in QuestDB, to large-scale distributed jobs in Spark, teams can rely on a single source of truth while keeping everything efficient and consistent.
To see how much the choice of format matters, let's look at a real example. In the next section, we will combine Parquet with QuestDB to show the impact in practice.
Real-World Finance Example
As mentioned earlier, a single trading day for S&P 500 futures can produce around 800 million rows. When ingesting at that scale, QuestDB's write-ahead log (WAL) and native columnar store are the best option to query with minimum latency and keep up with real-time workloads. But as data accumulates, storage volumes grow quickly. That's where Parquet comes in: converting older partitions to Parquet dramatically reduces footprint thanks to its column-based compression. Many financial fields repeat or vary only slightly, so compression is highly effective. File sizes shrink by an order of magnitude, which saves disk space, speeds up transfers, and makes historical queries far more efficient.
For this example, we will work with exactly that kind of dataset. Our goal is to track how the bid-ask spread evolves over the trading day, particularly around major events. This is a common liquidity analysis task for analysts and quants.
Here is the database table we will use for the exercise:
CREATE TABLE 'top_of_book' (timestamp TIMESTAMP,symbol SYMBOL CAPACITY 16384 CACHE,venue SYMBOL CAPACITY 256 CACHE,expiry_date TIMESTAMP,strike DOUBLE,option_type SYMBOL CAPACITY 256 CACHE,side SYMBOL CAPACITY 256 CACHE,action SYMBOL CAPACITY 256 CACHE,depth LONG,price DOUBLE,size LONG,bid_size LONG,ask_size LONG,bid_price DOUBLE,ask_price DOUBLE,bid_count LONG,ask_count LONG,ts_event TIMESTAMP,ts_recv TIMESTAMP,venue_description VARCHAR) timestamp(timestamp) PARTITION BY HOUR WAL;
Using Parquet with QuestDB
We ingested a few days of data into the top_of_book table using the ILP protocol. A full trading day of data contains
761,750,126 rows. Once in QuestDB, with no compression, we have these partitions:
# Native data formatdu -h --total /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12*2.9M /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T06.4133618G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T07.4132826G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T08.4132914G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T09.4133014G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T10.4133115G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T11.4133219G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T12.4133324G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T13.413343.0G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T14.41335130G total
At this rate, we are going to be using over a terabyte of data for this table in just over one week. Of course we can enable ZFS compression in QuestDB, and the data would shrink to ~28G, meaning it would take us more than 1 month to reach a terabyte of storage.
Let's see how Parquet can help here. After inserting the data, we can alter the table to convert one or more partitions to Parquet format:
ALTER TABLE top_of_bookCONVERT PARTITION TO PARQUETWHERE timestamp IN '2025-06-12';
WARNING
Converting partitions in-place is experimental right now. Please read more about the limitations and risks at the Parquet Export and Conversion Guide.
We can track the conversion with SHOW PARTITIONS. Once complete, the disk space usage looks like this:
# Parquet converted formatdu -h --total /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12*96K /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T06.413461.1G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T07.413381.6G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T08.41339834M /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T09.41340808M /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T10.41341877M /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T11.413421.2G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T12.413431.4G /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T13.41344174M /data2/qdb_root_spx/primary/db/top_of_book/2025-06-12T14.413457.8G total
Compression ratios will vary depending on the table data, and we can fine tune them with some parameters in QuestDB, but we can now see how we could store over 4 months of data until we reached 1 terabyte of storage.
An important detail here is that once data has been converted to Parquet, we don't need to worry about whether each partition is still in QuestDB's native format or already in Parquet. Queries run seamlessly across both types within the same table, so you just write SQL as usual and let QuestDB handle it under the hood. Now that the dataset is loaded and ready, we can start exploring market quality metrics. One useful measure is bid-ask imbalance, which helps identify whether liquidity is tilted toward buyers or sellers at a given moment.
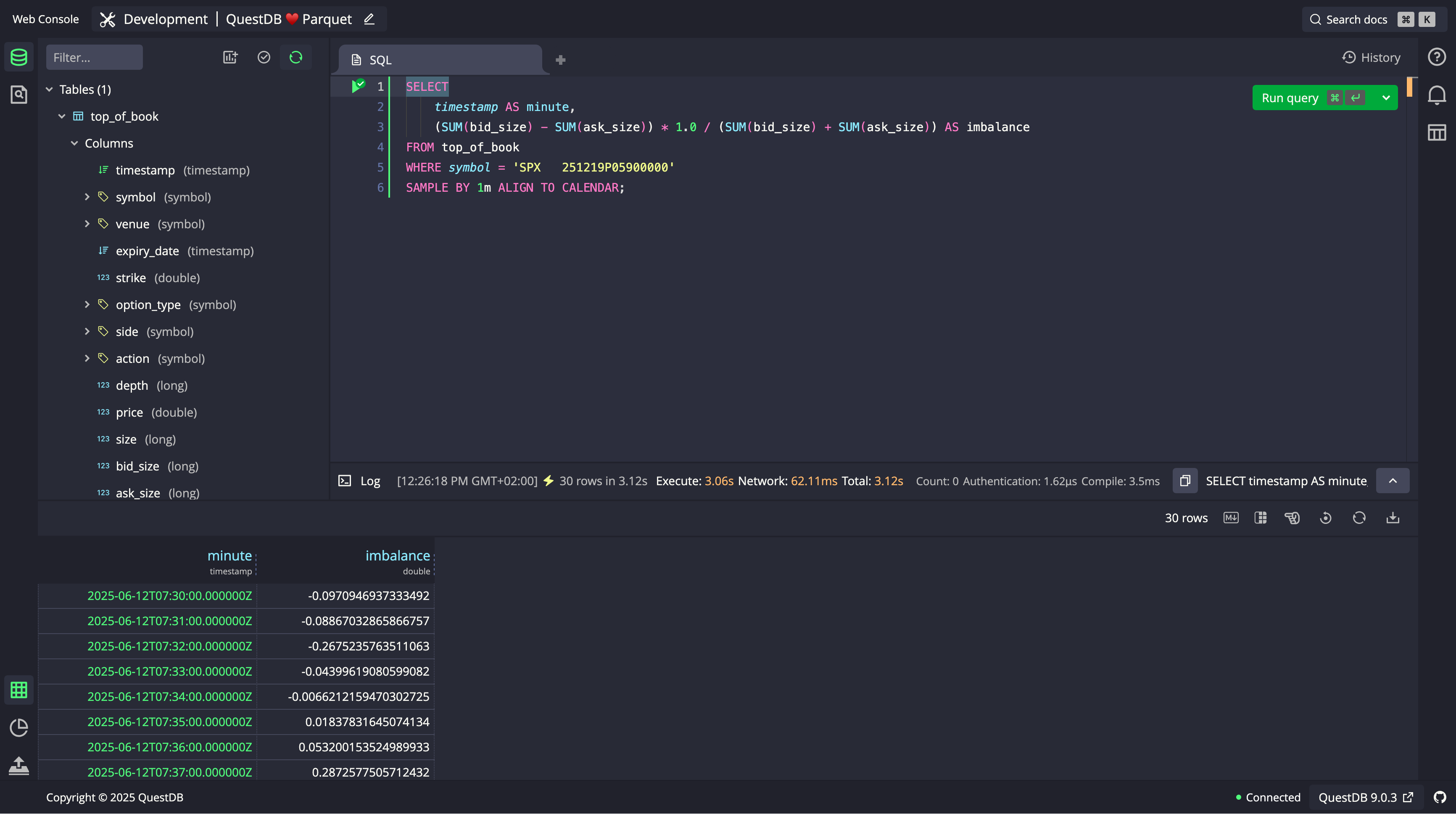
The calculation looks at the total bid and ask sizes. If the ratio is above 0, it means there is more demand on the
buy side; if it falls below 0, the market is leaning toward selling. The further the value is from zero, the stronger
the imbalance in either direction.
Here's a simple query to compute it over one-minute intervals:
SELECTtimestamp AS minute,(SUM(bid_size) - SUM(ask_size)) * 1.0 /(SUM(bid_size) + SUM(ask_size)) AS imbalanceFROM top_of_bookWHERE symbol = 'SPX 251219P05900000'SAMPLE BY 1m;
The screenshot below shows the imbalance values sampled at a one-minute rate. We are not using any time filters here, so QuestDB is aggregating data from all the partitions in the table, those converted to Parquet, and those in native format.
Exporting Data as Parquet Files
So far, we've seen how to convert older partitions in place, with partitions remaining under QuestDB's control. But sometimes we may want to export a whole table or the result of a query as Parquet in order to share the data externally. For this, QuestDB provides an API export1 endpoint, which allows us to write out Parquet directly.
By calling the /exp endpoint of the QuestDB API, we can manually export any table or query in Parquet format with one call.
curl -G \--data-urlencode "query=\SELECT timestamp AS minute, \(SUM(bid_size) - SUM(ask_size)) * 1.0 / \(SUM(bid_size) + SUM(ask_size)) AS imbalance \FROM top_of_book \WHERE symbol = 'SPX 251219P05900000' \SAMPLE BY 1m;" \'http://your_host:9000/exp?fmt=parquet' \> /tmp/exp.parquet
The export can also be initiated via SQL using the COPY statement.
Reading External Parquet Files
QuestDB doesn't only support Parquet files as an output, but also as an input. If we already have external Parquet files
that we want to examine quickly, QuestDB has native support through the read_parquet() SQL function. We can query those files directly, no need for bulk imports or complicated setup.
Just drop the .parquet file into the import directory and start querying.
SELECT timestamp, symbol, venue, bid_price,ask_price, bid_size, ask_size, price, sizeFROM read_parquet('path/to/exp.parquet')LIMIT 1;
As you can see in the screenshot, QuestDB returns the data exactly as if this was a file under QuestDB control.
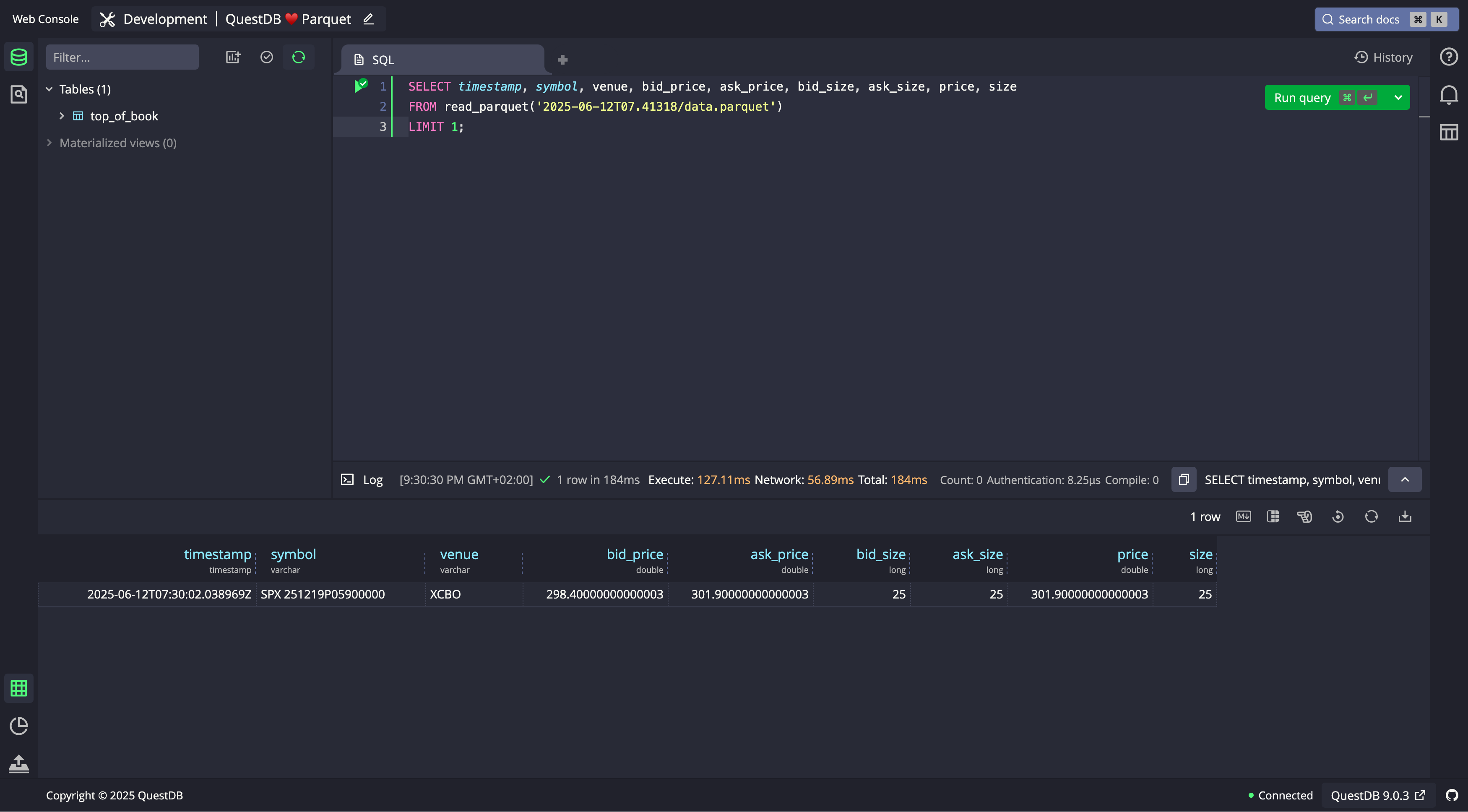
Reading from an external file is not ideal for performance-critical applications, as QuestDB is missing some of the table metadata in this case (for example, which is the designated timestamp), and it cannot perform some optimizations. For a one-off query, reading external Parquet files is fine. But if you expect to run multiple queries, you can use SQL to read from the external Parquet file and into QuestDB tables:
INSERT INTO top_of_bookSELECT * FROM read_parquet('path/to/data.parquet');
Conclusion
Parquet is a perfect fit for market data: it shrinks files, can speed up queries, and works everywhere. For finance teams, that means less storage, faster analysis, and smoother integration across the stack.
QuestDB adds the missing piece, real-time ingestion and direct support for open formats. We can capture live data, export it to Parquet, or run queries directly on Parquet files. In pure Open Source spirit, you get no vendor lock-in.
If you're working with large time series datasets, try QuestDB with Parquet and see how well it fits into your workflow.
1As of this writing, the Parquet API export is not yet generally available, but will be released very soon. Status can be tracked at this PR