Real-time analytics with an all-in-one system: Are we there yet?
Real-time data analytics have been around for more than a decade, and the ecosystem is quite mature. However, a robust pipeline requires a deep amount of hand-crafted integration work.
After all, there are many powerful and useful parts in a typical real-time analytics toolchain. This is especially evident in use cases which combine insights over a full historical dataset, while also needing to handle new data every second from the real world.
While there are strong multi-product choices today, we want to know what would happen if a single product tried to handle the full range of real-time analytics challenges.
Can any emerging entrants become a true one-stop-shop solution?
Use case: aggregate functions over time slices
To better understand the overall challenge, consider requirements behind an open-high-low-close (OHLC) or candlestick chart used for trading applications in financial markets. You can get a chart at various levels of detail: live updates from the current trading day, seamlessly combined with the data from the past week, month, year, and so on.
To calculate the values for these charts, you have to partition the full dataset into time slices of various sizes, and find the min/avg/max values for each slice. These time ranges can be significant.
This is an example of a general and versatile class of real-time analytics: aggregate functions over time slices.
There's a lot going on under-the-hood to make this work well and fast. To illustrate, we'll look at typical real-time analytics system design today, and then we'll contrast that with a look at several database systems.
Main challenges
Like with financial charts, we tend to perform real-time analytics on a dataset that is both massive and rapidly growing. This creates several tough challenges:
- Storing massive data volumes cheaply and effectively
- Returning robust results at no more than few seconds of latency
- Returning correct results after updates to existing data
- Keeping data access to a minimum — access itself costs money
As the volume of the collected data grows, storage costs balloon. Unless you have your own datacenter and a team committed to continuously procuring and maintaining storage devices and systems, you'll end up as a client of cloud storage, such as Amazon S3, Azure Blob, or Google Cloud Storage.
This creates a barrier in your software stack — one type of storage for fresh data, and another for historical data. You need a system that seamlessly jumps over the barrier and serves you the analytic results you need from any period you want:
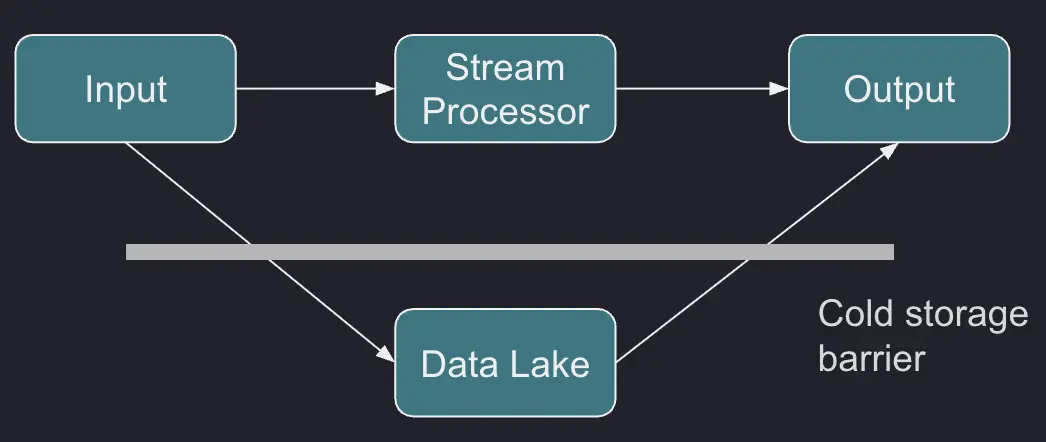
The cost of just keeping your data is relatively low, but the story quickly changes once you need to access it. Your system must ensure it accesses only the data which it absolutely needs.
Basically, if the data didn't change, you shouldn't need to access it again. That's expensive and inefficient. Instead, it's better to store and reuse the results of the analytics you performed once.
In this scenario, the greatest challenge is an update to the historical data: you must keep the volume of accessed data low, and yet make sure you update everything that needs to be updated.
At the same time, the system must deal with the fresh data that just came in. It must stay on top of possibly millions of events per second, and come up with the right answers about what just happened in the world.
Modern real-time analytics pipeline
In a typical modern setup, we are likely to use two separate systems, each specialized in solving one challenge. We use Apache Kafka to ingest the data, and then fork the data pipeline so that one fork goes to the system optimized for low-cost storage, and the other to the system optimized for real-time event processing.
For the recent data, we can use a stream processing engine like Apache Flink. It takes in the events as they occur, aggregates them in memory, and outputs live results with minimal latency:

For the historical data, the starting point is cheap storage. The primary choice for most companies being cloud storage like S3 or Azure Blob Storage. This kind of storage comes with higher access latency. It's completely unstructured (the unit of data is a blob), and immutable.
That means you need another system that builds upon this foundation to provide higher-level services. One option is using a cloud-based data lake platform, like Snowflake; another is an open-source analytics tool like Spark:

This kind of setup obviously has several moving parts, but there's even more when you take a closer look. For example, how do you access the output of realtime stream processing?
A streaming engine like Apache Flink only solves the computation concern; its output doesn't automatically come in a form ready for ad-hoc query access.
One option is storing the results in a general-purpose database, like Postgres. Then you can use the same database to store the results for historical data as well, and finally there should be an API frontend component that queries the database.
Another option is to treat Kafka itself as the source of truth. Flink outputs its results to a Kafka topic, and then the API frontend component loads them into RAM and serves them. If the component fails, after restart it can just rescan the Kafka topic. It can also use a local, embedded database.
On the data lake side, the main challenge is doing the least amount of work possible while maintaining the correctness and completeness of the stored analytics results. You can process the past day's worth of data during the night, when the handover from the real-time system to the data lake occurs.
As for updates to the older data, you can use Delta Lake, Apache Iceberg, Change Data Capture (CDC), and other architectures to track what's changed and prepare a batch work order containing the affected parts of the dataset.
All these parts must account for, and be resilient to, failures. To manage this, you need infrastructure that monitors operations and retries failed ones.
Putting it all together, we get a rough outline of a modern hybrid system for realtime data analytics:
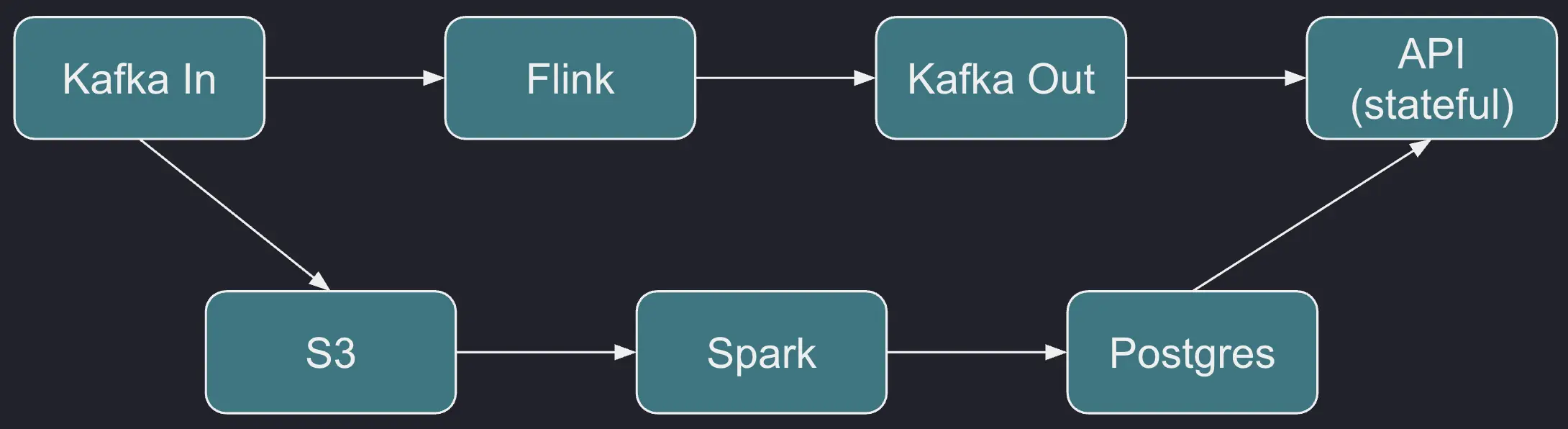
Since the need for real-time analytics has become mainstream and widespread, there's an increasing demand for a simpler system, one that would automatically handle both historical and new data in a uniform fashion, and simply provide you with the results you want.
Simplification with an all-in-one product
An emerging option for this workload is a streaming data lakehouse system.
Products from diverse categories have been converging on it, such as data lake products, real-time streaming engines, and time-series databases. Each one is adding features from the others, in a bid to build one complete, integrated system that handles all the concerns automatically:

We'll focus on systems that originate in the time-series database category.
In this category, the best paradigm for real-time analytics is that of the materialized view. A closely related concept is continuous aggregation.
In its essence, a materialized view is a SQL query in solid-state form: its results are persistent in a database table, available at no computation cost. You can get them using a trivial query that doesn't need to spell out any of the business logic needed to calculate them. A materialized view is as convenient to create as it is to access.
But to work for our use case, the database must make sure the materialized view is always up to date — and that's where things get interesting. Databases vary widely in their support for low-latency updates of materialized views, and those that do have good support vary widely in their approaches.
We found the following databases to be good at low-latency materialized views: TimescaleDB, ClickHouse, and InfluxDB. At QuestDB, we've recently introduced materialized views, and are constantly improving their performance and ergonomics.
TimescaleDB
TimescaleDB is an extension on Postgres and thus benefits from its maturity. This is how you implement continuous aggregation:
CREATE MATERIALIZED VIEWwith the desired query. This runs the query against the existing data, and saves it to the table you named.SELECT add_continuous_aggregate_policy(...)to schedule a task that updates the materialized view at a fixed time interval.
When you query the materialized view table, TimescaleDB uses a hybrid approach: it takes everything available from the table, and for anything that's missing it runs the aggregation query against the base table.
Thus, you always get the full results, regardless of when the scheduled task last ran. However, the query's runtime will go up in proportion to the volume of the missing materialized results.
Given this, you'll have to find a balance that minimizes the system load induced by the scheduled task, and the runtime of the query. The scheduled task can be configured to scan only a recent portion of the base table, which limits the impact on system load, but leaves earlier data permanently stale. You can also schedule another, less frequent task that updates the full table.
We should also note that TimescaleDB, due to its Postgres fundamentals, isn't as optimized for the ingestion of massive amounts of time-series data. QuestDB typically ingests data at a rate many multiples faster. It's also quite complex to scale horizontally. This negatively impacts the resource and maintenance costs.
TimescaleDB supports tiered storage in its Cloud edition. Once properly set up, you can query the data across tiers transparently. However, setup and configuration is quite involved and requires knowledge of both Postgres and TimecaleDB concepts. You can't directly update the data in cold storage. You must go through the manual steps of "un-tiering" it, updating and "re-tiering" it.
TimescaleDB benefits from the maturity of Postgres in terms of the support for monitoring and diagnostics of the tasks that keep the materialized view up to date. You can also integrate with Prometheus.
ClickHouse
ClickHouse also supports CREATE MATERIALIZED VIEW, but with completely
different semantics. This is how you use it:
- Manually
CREATE TABLEthat will hold the materialized view. Specify the correct table engine:SummingMergeTree(). CREATE MATERIALIZED VIEW ...— this sets up a scheduled task that will run whenever you insert new data, and specifies the aggregation expression. Existing data won't be processed.- Manually backfill the table with existing data.
Since ClickHouse runs the aggregation whenever you insert data, the latency of the aggregated results is very low. However, updates and deletions aren't reflected and need to be handled manually.
ClickHouse supports tiered storage in its Cloud edition. It will automatically move the older data to cold storage using its TTL feature. You can't directly update the data in cold storage, you must take manual steps to move it back to hot storage, delete the outdated data, insert data with updates, and move back to cold storage.
The materialized view table is like any other, and allows arbitrary insert/update/delete actions, as well as schema changes. This makes it prone to incorrect data and errors in the continuous aggregation process.
ClickHouse is great at raw ingestion performance, but compared to TimescaleDB, it's not as mature for monitoring, diagnostics, and issue resolution.
All told, maintaining a large number of materialized views is a complex task, with lots of hand-crafted code and tooling needed.
InfluxDB
Basic steps to create continuous aggregation in InfluxDB resemble those for ClickHouse:
- Create the destination table (bucket in InfluxDB terminology)
- Create a scheduled task that runs continuous aggregation
- Manually backfill the existing data
Unlike ClickHouse, and more similar to TimescaleDB, this task runs on a fixed time-interval schedule and isn't triggered by inserts. It only looks at the recent data, and you can configure exactly how recent. It doesn't automatically backfill, so it requires a manual backfill step.
This mechanism creates a conflict between low latency and low system load, because you have to set a short interval to get low latency. But on the flip-side, the task will rescan the whole specified range every time. Unlike TimescaleDB, there's no hybrid mechanism that fills the gaps by running a query on the base table.
InfluxDB supports tiered storage in its Enterprise and Cloud editions. You can set up a data retention policy that copies the data to cold storage, where it remains available for querying.
Since InfluxDB is purpose-made for monitoring and alerting, the support in this area is solid. To this end, the company developed a whole ecosystem of tools: Telegraf, Chronograf, and Kapacitor.
InfluxDB's main drawback is widely considered to be its lack of full SQL support. Given that it requires its own DSL, it gives the impression of a special purpose tool. While it supports the use case of continuous aggregation itself, there's less support for more general and powerful data analytics on the same dataset.
So, InfluxDB alone usually isn't enough for all the things you need to do with the data.
QuestDB
With QuestDB, there's only one step to set up continuous aggregation:
CREATE MATERIALIZED VIEW ...
This creates the materialized view table, backfills it with the results of processing the existing data, and sets up the aggregation task to run on all changes to the base table, including updates and deletions. The task is fired immediately when changes occur, but it may be delayed when system load is high.
This simplicity is a key part of QuestDB's vision for a single-source real-time analytics system. By handling both historical and fresh data through the same materialized view mechanism, we eliminate the need for separate systems and complex integration work. Whether you're querying data from last year or the last second, you use the same SQL interface and get consistent results.
Another nice aspect of QuestDB's materialized views is that you can cascade them — a materialized view's base table can be another materialized view. This allows you to create a very efficient pipeline of aggregations at different levels of granularity.
QuestDB keeps maintainability in focus and exposes the status of materialized views through the SQL interface:
SELECT * FROM materialized_views()
With this, you can monitor refresh lag, and detect and diagnose failures.
While the computations you can use with materialized views are limited to aggregate functions over time slices, QuestDB's general querying power is quite robust. It supports JOINs, window functions, Common Table Expressions, nested SELECT expressions, and so on.
However, in the current version (8.3.1), QuestDB's materialized views aren't very resilient to schema evolution. The materialized view will get invalidated if you DROP or ALTER a column, even when the materialized view doesn't depend on it.
QuestDB supports tiered storage in its Enterprise edition. It can keep your data in cold storage, in Parquet format, and query it without converting back to its native format.
Overall, this is a significant step forward for this use case, and its near-future roadmap contains some improvements:
-
Better resilience of materialized views to schema evolution. You'll be able to manipulate non-dependency columns without breaking the materialized view.
-
Support for a refresh policy based on a fixed time interval. If you align it with the time slice interval, this will ensure the materialized view is always fresh, with significantly less impact on system load.
Conclusion
The journey from complex, multi-system architectures to unified solutions is well underway. Each database we examined brings valuable pieces to the puzzle: TimescaleDB's hybrid query approach, ClickHouse's raw performance, InfluxDB's monitoring expertise, and QuestDB's simplified materialized views.
The database systems we reviewed all seem to have many building blocks needed, but none of them seems to be fully ready to take over the all-in-one real-time analytics system.
The ideal system would combine the best of these approaches: effortless setup and maintenance, consistent performance across all data ages, and a single interface for both real-time and historical analytics. While we're not quite there yet, the convergence of these technologies suggests that the one-stop-shop solution for real-time analytics is within reach.
As these systems continue to evolve and borrow from each other's strengths, we can expect to see more solutions that truly unify the real-time analytics experience. The future belongs to systems that can handle the full spectrum of analytics needs without requiring complex integration work or specialized knowledge of multiple technologies.