QuestDB 9.0: Armed with Arrays
QuestDB 9.0 is a big one! We’ve added N-dimensional arrays, calendar-savvy materialized views, increased data-deduplication efficiency, computed smarter JOINs, and refreshed the Web Console's UX — all while doubling down on robustness.
Whether you’re already running QuestDB in production or spinning up your first instance, 9.0 is a big step forward.
Without further ado, here are the core additions.
N-dimensional Arrays
QuestDB 9.0 debuts true N-dimensional Arrays. These are true shaped-and-strided, NumPy-like arrays — common array operations (e.g. slicing, transposing) are handled with zero copying. Instead, the underlying buffer is shared between different operators, whether the arrays are stored on-disk or in-memory. The data is contiguous and stored as a true tensor rather than nested lists.
Enjoy zero-copy slicing, transposing, cumulative ops, and aggregates. Ideal for market data order-book depth or ML weight snapshots, with more data types on the way. Run spread, liquidity, and imbalance analytics in a single SQL query — no ETL, no UDFs.
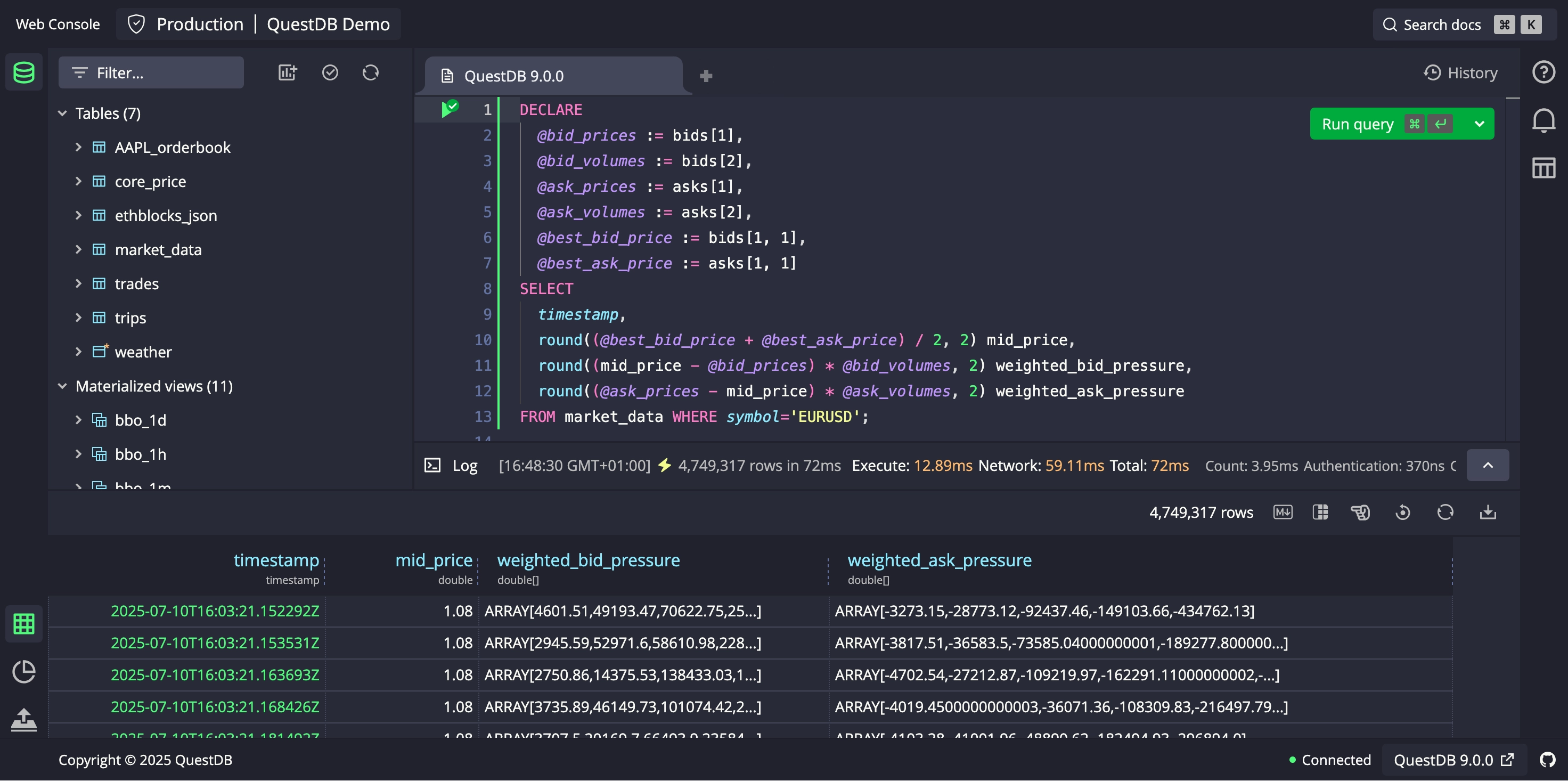
Our first public beta supports DOUBLE[] of any shape. Many core array
operations are included in this release, and we will be rapidly releasing more.
See our guides for using arrays with order book data.
Binary Line Protocol
To push those arrays at wire speed, QuestDB now speaks binary DOUBLE[] /
DOUBLE.
This raises the bar even higher for high-throughput ingestion, especially for array-based data such as order-books. Lower bandwidth usage, faster server-side processing, it all adds up!
With QuestDB's existing support for zero-copy Pandas dataframe ingestion, its never been easier to get your N-dimensional array data into QuestDB:
import pandas as pdfrom questdb.ingress import Senderdf = pd.DataFrame({'symbol': pd.Categorical(['ETH-USD', 'BTC-USD']),'side': pd.Categorical(['sell', 'sell']),'price': [2615.54, 39269.98],'amount': [0.00044, 0.001],'ord_book_bids': [np.array([2615.54, 2618.63]),np.array([39269.98, 39270.00])],'timestamp': pd.to_datetime(['2021-01-01', '2021-01-02'])})conf = f'http::addr=localhost:9000;'with Sender.from_conf(conf) as sender:sender.dataframe(df, table_name='trades', at='timestamp')
We'll follow this up soon with smarter clients, bringing closer integration with data deduplication, schema evolution, and replication fail-over.
Materialized Views
Materialized Views receive significant upgrades - efficient writes with the new
replace commit mechanism, support for self-UNION queries, the ability to delay
or defer a refresh, and three new view refresh modes:
TIMERrefreshes (now stabilised), allowing you to refresh the view after a regular time interval.MANUALrefreshes, which are entirely user-controlled.PERIODrefreshes, with more explanation below.
PERIOD refresh is the most featureful mode to date, bringing time-zone aware,
calendar-scheduled refreshes, only including complete buckets of data. This has
great potential, especially for users with globally distributed use cases.
One view can summarise NYSE trades right after the New York bell, while another waits for Tokyo’s close, all with the same clean syntax:
CREATE MATERIALIZED VIEW trades_latest_1dREFRESH PERIOD (LENGTH 1d TIME ZONE 'America/New_York' DELAY 2h) ASSELECTtimestamp,symbol,side,last(price) AS price,last(amount) AS amount,last(timestamp) AS latestFROM tradesSAMPLE BY 1d;
MANUAL refreshes allow you, the user, to integrate materialized views directly
with your scheduling platform. You can take control of the refresh, triggering
it exactly when you need it. But better yet, each refresh will still be
incremental, meaning you don't have to trade efficiency for better control.
To recap, see the full materialized views documentation.
Data Deduplication
One of the important performance enhancements brought in 9.0.0 is increased data deduplication efficiency.
DEDUP is a simple way to safely update and re-send data, in a way that is
compatible with Materialized Views.
It has a very low overhead if only a few rows need deduplicating, around 8%.
With 9.0.0, we've added an optimisation to skip unchanged data, minimising I/O overhead when reloading lots of identical, deduplicated data.
We'll soon follow this up with a new deduplication variant, which will preserve the original row instead of replacing it.
Web Console
Our web console sports a fresh coat of paint, bringing long-sought-after features.
Firstly, each query is marked by its own run arrow and selection, making it easy
to see at a glance where your semicolon-delineated boundaries lie. Also, you can
now obtain query plans by right-clicking on the run arrows, helping you better
understand and debug troublesome queries—no more typing out the EXPLAIN
keyword, only to delete it straight afterwards!
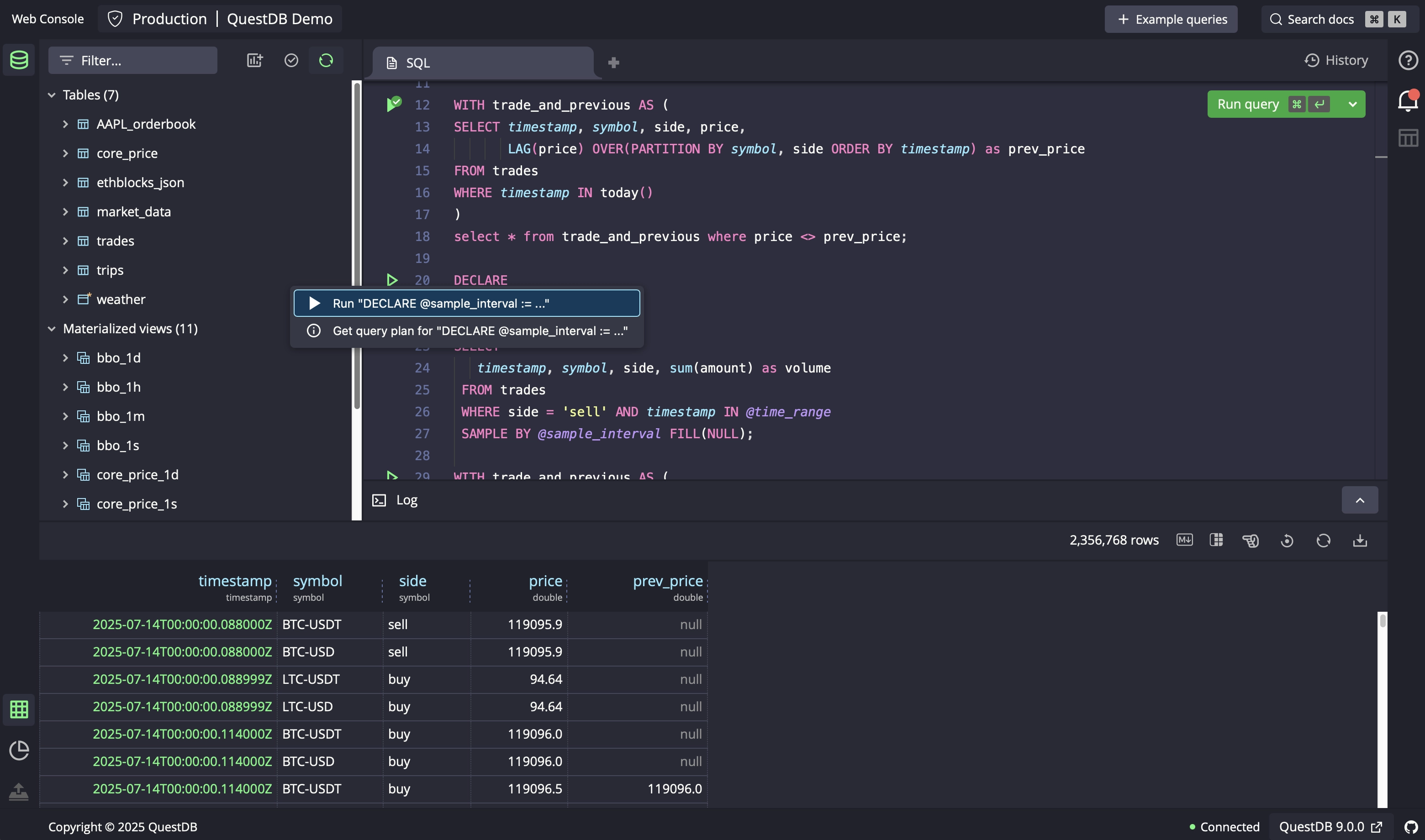
The console can now execute multiple queries in one go—drag-select or hit Run All—with results captured in a new Query Log. Ideal for migration scripts, and you can choose to halt the batch on the first error.
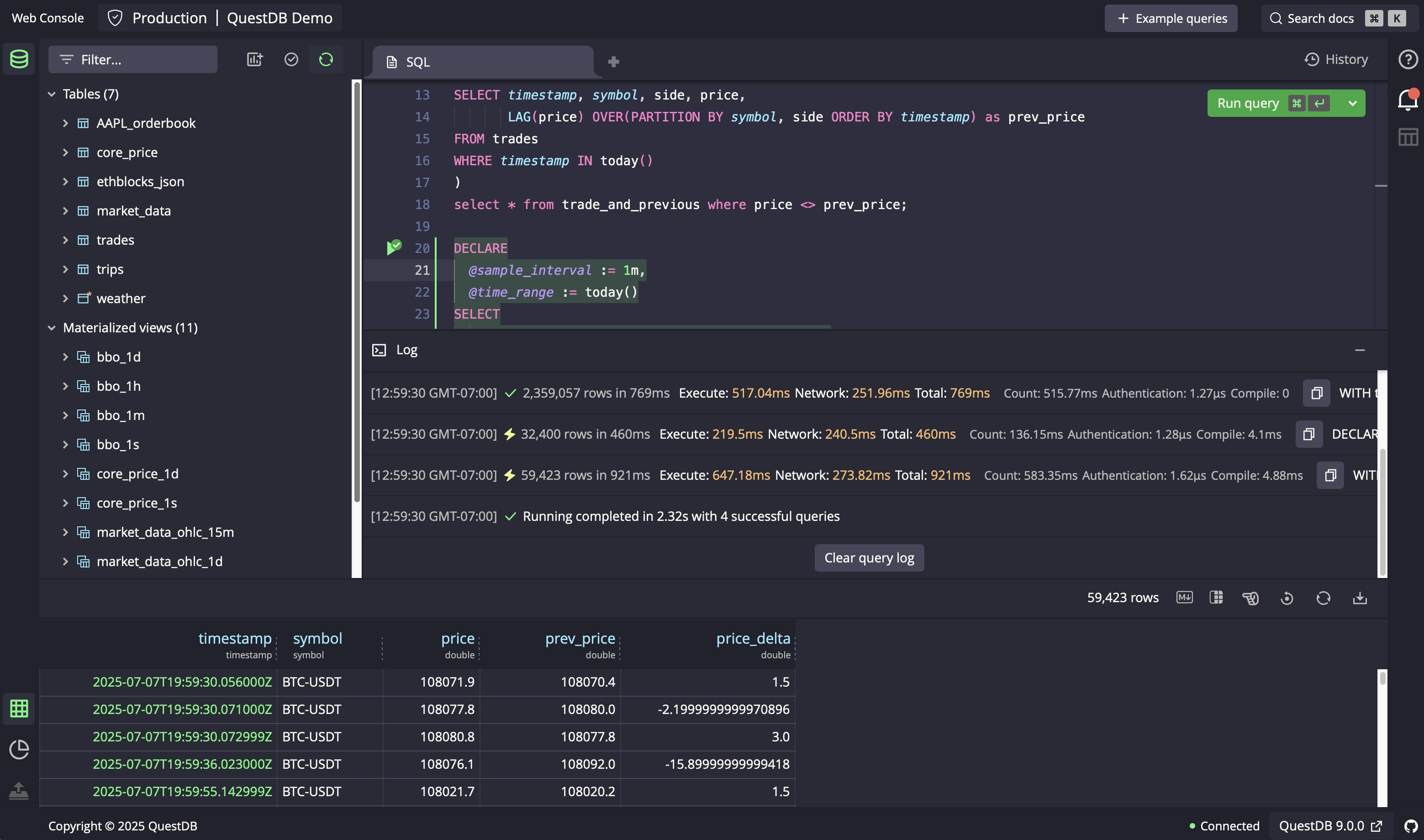
We've refreshed our Web Console documentation, and invite you to take a tour of our new features.
ASOF JOIN with TOLERANCE
ASOF JOIN is a quick and easy way to merge different time-series together. We
recently added an
alternative binary-search algorithm
to better handle matching illiquid symbols.
In a follow-up, we've also added a
new TOLERANCE parameter,
which allows to bound your matches to a sensible time. This is handy if you have
quantities that 'expire' after a certain time-period.
Here's an example query, in which we match the last 6 top-of-book bid prices against the offer prices, with a 1 second tolerance.
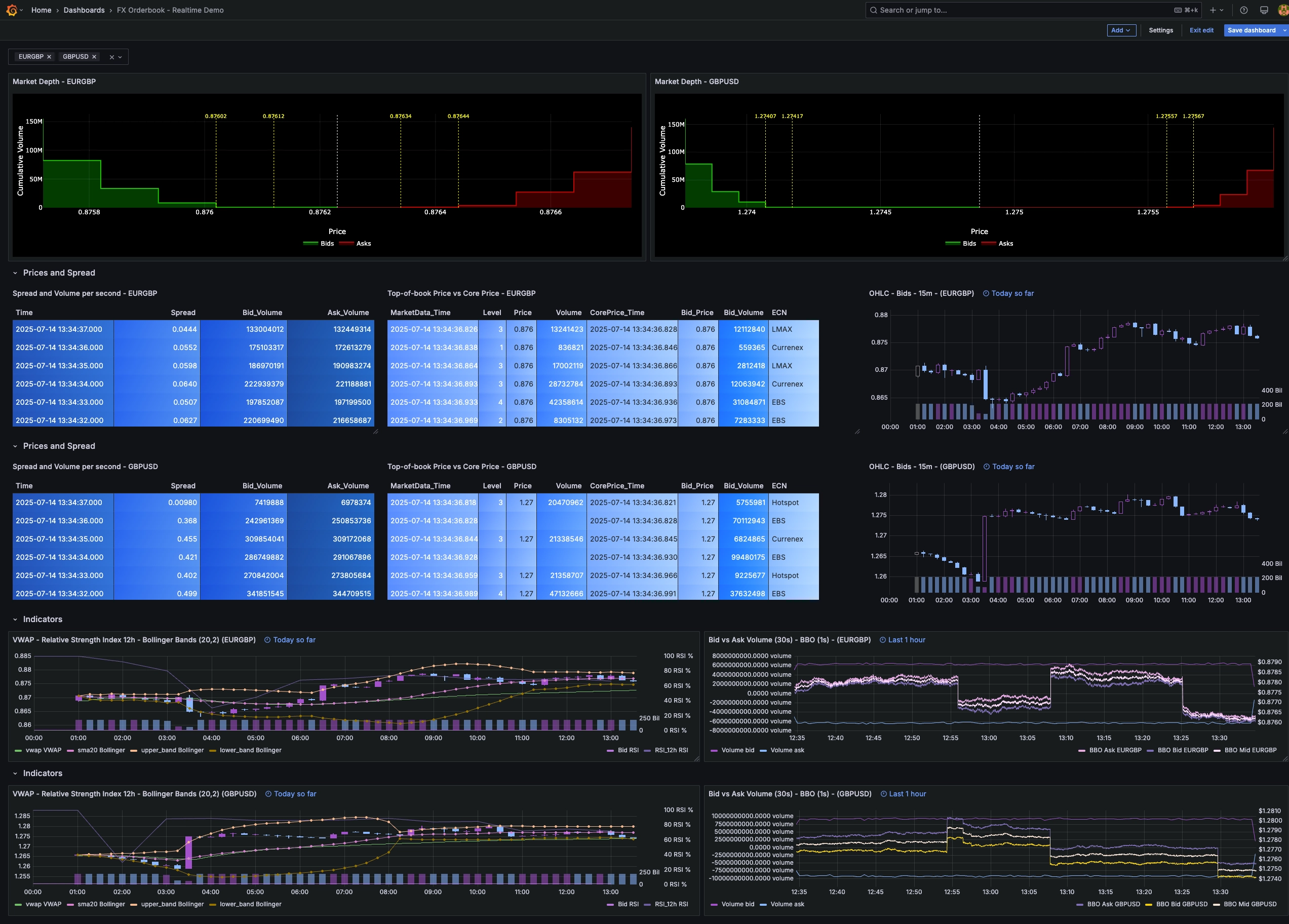
DECLARE@level := insertion_point(bids[2], bid_volume),@price := bids[1][@level]SELECTmd.timestamp market_time,@level level,@price market_price,cp.timestamp core_time,cp.bid_price core_priceFROM (core_priceWHERE timestamp IN today()AND symbol = 'GBPUSD'LIMIT -6) cp-- Match the bid to its nearest price within one second.ASOF JOIN market_data mdON symbol TOLERANCE 1s;
This query is one of many that feature on our new FX order-book dashboard. Here's a sneak preview:
Roundup
9.0 is a big milestone, yet just another waypoint on our roadmap.
We'd like to give a huge thanks to everyone who opened issues, pinged us on Slack, or shared production insights—your feedback powers QuestDB.
Look out for what's coming next - Parquet full-release, nanosecond timestamps,
and pub-sub subscriptions!
It's never been a better time to get started, so download QuestDB now!
For any questions or feedback, please join us on Slack or on Discourse.
See also our prettier release notes page.