Highly Available Reads with QuestDB
QuestDB is designed for high performance and reliability, and under normal circumstances, a single node can handle substantial load with ease. But in production environments, even the best systems can face disruptions: network issues, storage limits, power outages, or routine maintenance can all cause a node to go offline.
If you're building mission-critical or latency-sensitive applications, you want to make sure that read queries don't fail just because a single node is down. QuestDB Enterprise supports built-in replication, so you can distribute read traffic across replicas and keep queries running even during outages.
PostgreSQL-compatible clients, by default, don't have visibility into replication state. This applies to both PostgreSQL and QuestDB. If a node goes down, the client won't automatically fail over unless you configure it to.
You can handle this at the infrastructure level using DNS failover, floating IPs, or a proxy between your servers and clients. But there's no need to complicate things on the server side. Most Postgres clients already support multiple hosts in the connection string, making it easy to implement client-side failover.
In this post, you'll learn how to implement high-availability reads using standard PostgreSQL clients and basic reconnect logic. If you don’t have a replicated cluster yet, you can simulate one locally and walk through examples in several languages.
Overview of replication using QuestDB Enterprise
In QuestDB Enterprise, replicas stay in sync automatically, using object store to propagate any DDL, DML, WAL ingestion, or authorization change to all the replicas in the cluster. Adding or removing replicas, and having them catch up to a consistent state is fully automated. Your entire topology behaves as a single logical database.
✅ You change a setting? It's updated everywhere.
✅ You create a table? It's replicated.
✅ You ingest via ILP? All replicas see it.
No extra plumbing needed.
Client applications can use either the REST API or the PostgreSQL protocol to query data from whichever node in the cluster. If a node is not responding, the client needs to be aware it needs to connect to the next available node. When using the postgres protocol, we can take advantage of the multi-host feature supported by most clients.
Starting the demo nodes
We recommend to use your QuestDB Enterprise cluster, configured with at least one replica, to run this demo.
Simulating failover locally using QuestDB OSS (no replication)
If you'd rather not test against your production environment, or if you prefer to run the demo from a local development machine, you can simulate failover by creating a fake cluster using docker and starting several instances of QuestDB Open Source listening on different ports.
We are not doing any kind of replication in this case, as instances are completely unaware of each other, but since we only want to see how a client application can seamlessly failover reads, this simplified setup will do.
We’ll start three independent QuestDB instances on a single machine using Docker. Each listens on its own HTTP and
Postgres port. We’ll pass a unique environment variable (QDB_CAIRO_WAL_TEMP_PENDING_RENAME_TABLE_PREFIX) so we can
distinguish nodes later:
NOTE
This is not replication. These containers are completely independent. No writes or schema changes are shared between them. This setup is only meant to simulate failover for the client retry demo.
docker run --name primary -d --rm \-e QDB_CAIRO_WAL_TEMP_PENDING_RENAME_TABLE_PREFIX=temp_primary \-p 9000:9000 -p 8812:8812 questdb/questdbdocker run --name replica1 -d --rm \-e QDB_CAIRO_WAL_TEMP_PENDING_RENAME_TABLE_PREFIX=temp_replica1 \-p 9001:9000 -p 8813:8812 questdb/questdbdocker run --name replica2 -d --rm \-e QDB_CAIRO_WAL_TEMP_PENDING_RENAME_TABLE_PREFIX=temp_replica2 \-p 9002:9000 -p 8814:8812 questdb/questdb
To verify which node you’re connected to, run:
select value from (show parameters)where property_path IN ( 'replication.role', 'cairo.wal.temp.pending.rename.table.prefix')limit 1;
In QuestDB Enterprise, the output of the command will be primary or replica, as read from the replication.role
parameter. If using the fake cluster via containers, the output will be temp_primary, temp_replica1, and temp_replica2.
Now that you have several instances to test failover, let’s look at how to build client-side retry logic.
How HA reads work
PostgreSQL clients in most languages, support the standard postgres's libpq way of passing multiple hosts in the connection string. This lets the driver connect to the first available host, but, as per libpq itself, there’s no automatic reconnection if that host dies.
To make reads highly available, you need two things:
- List of nodes in the connection string.
- Retry logic to catch failures and connect to the next one.
This repository shows how to get highly available reads using standard postgresql libraries from Python, Java, C++, C#, Go, Rust, and Node.js.
We’ll show the Python version first, followed by Node.js, which uses a slightly different approach.
Python example
This Python example uses psycopg3. The
retry logic is simple: try to connect, catch failure, and try the next host.
TIP
Make sure libpq is installed on your system. This is typically included with PostgreSQL, or available via your package manager.
import timeimport psycopgCONN_STR = "host=localhost:8812,localhost:8813,localhost:8814 user=admin password=quest dbname=qdb connect_timeout=3"QUERY = """select value from (show parameters)where property_path = 'cairo.wal.temp.pending.rename.table.prefix'"""def get_conn():while True:try:conn = psycopg.connect(CONN_STR)print(f"Connected to {conn.info.host}:{conn.info.port}")return connexcept Exception as e:print(f"Connection failed: {e}")time.sleep(1)with get_conn() as conn:with conn.cursor() as cur:for i in range(250):try:cur.execute(QUERY)row = cur.fetchone()print(row[0])except Exception as e:print(f"Query failed: {e}")conn = get_conn()cur = conn.cursor()time.sleep(0.3)
The script will run the query 250 times, one every 300ms, and print the result. If you stop/restart your docker containers during the demo, you will see how the application seamlessly reconnects to the next available host, or it just keeps retrying until one is available if all hosts are down.
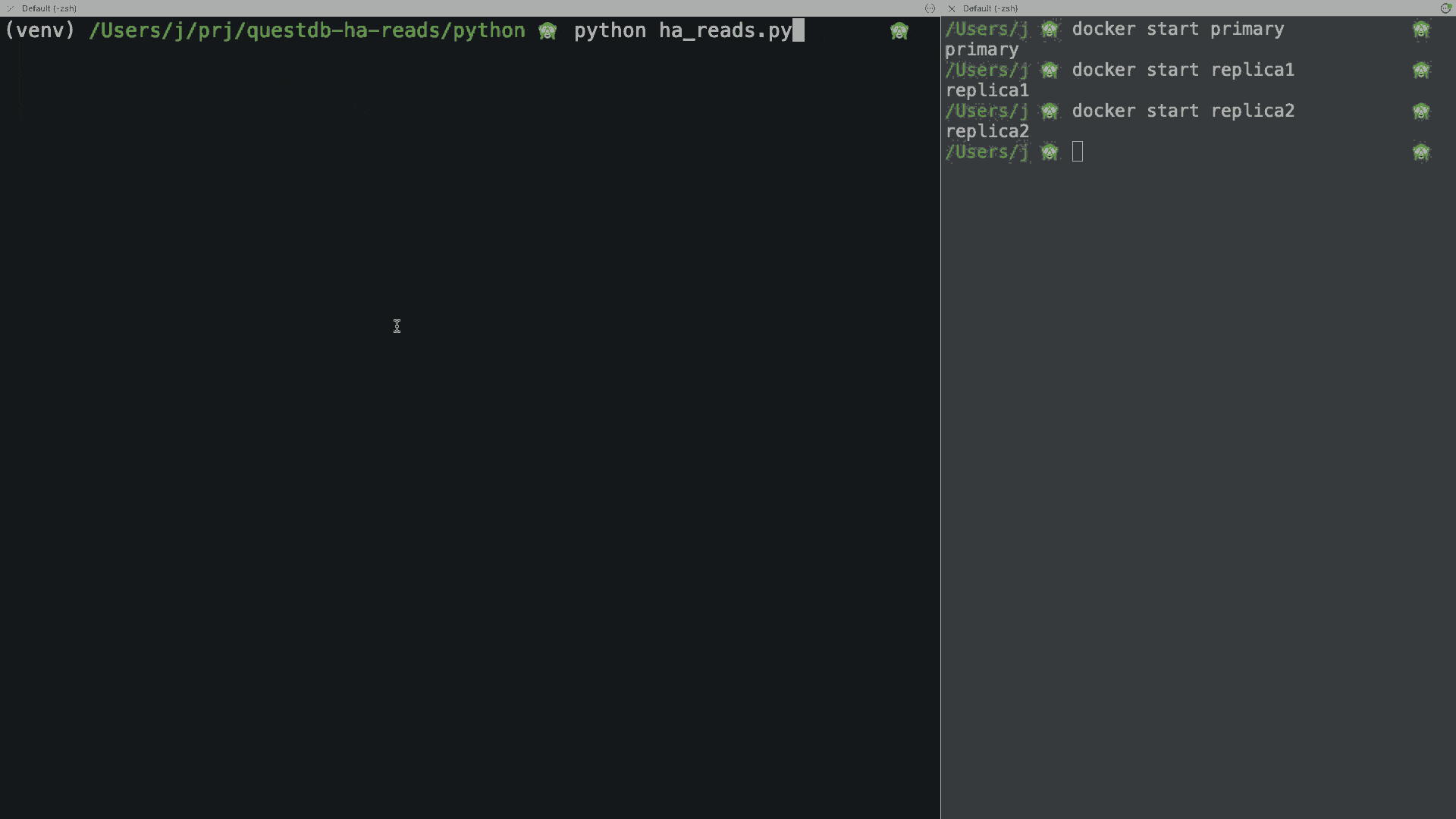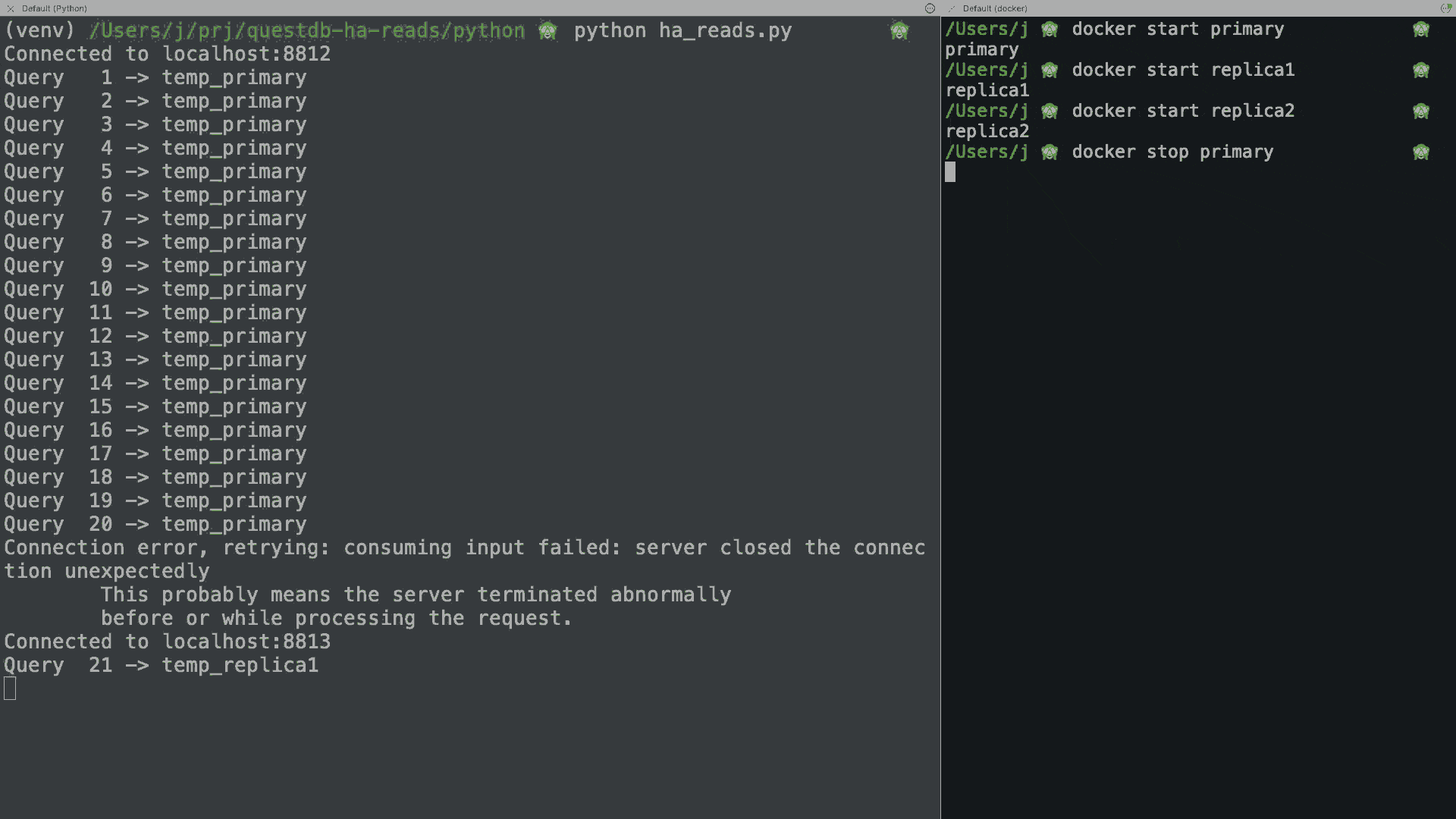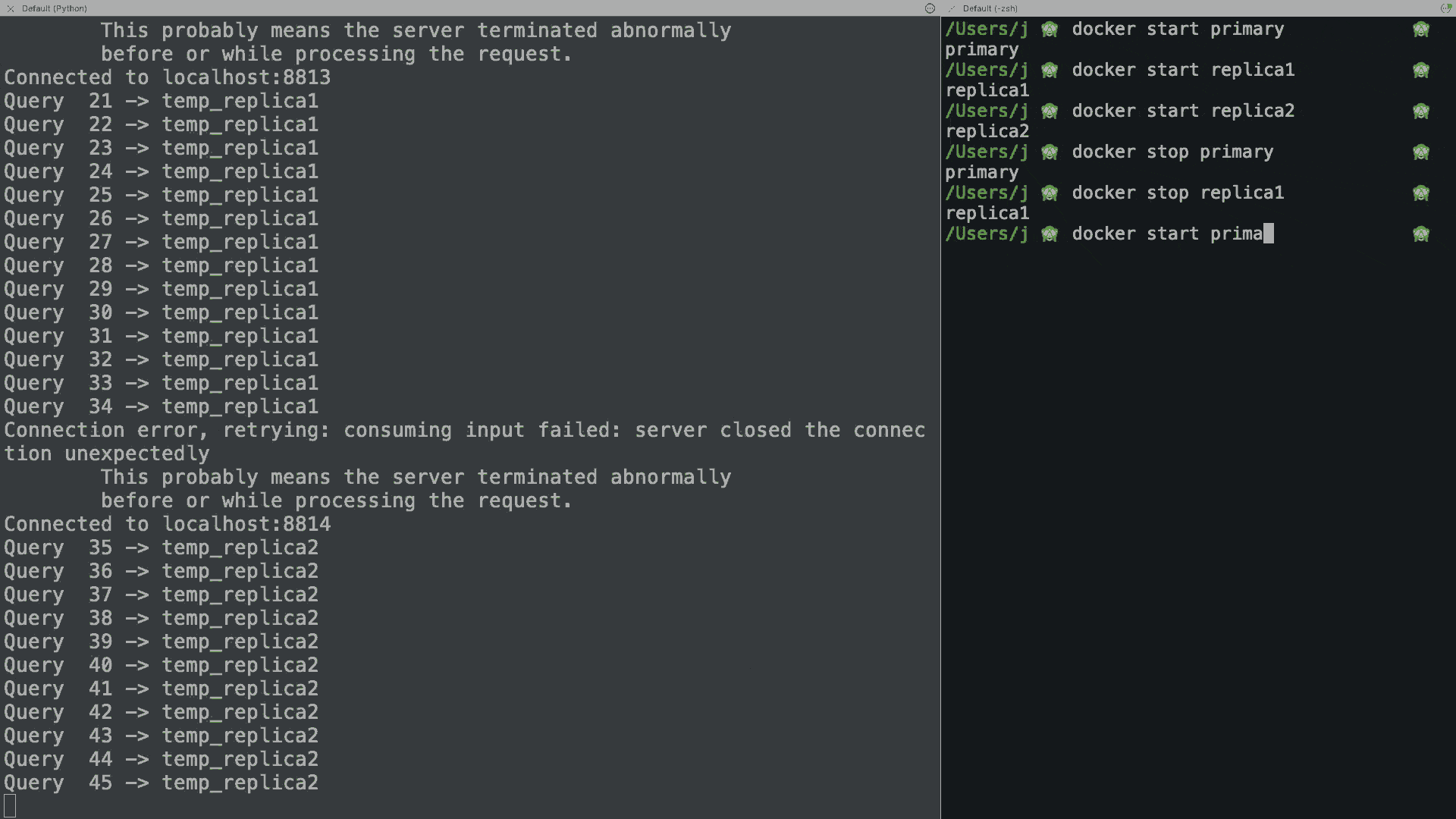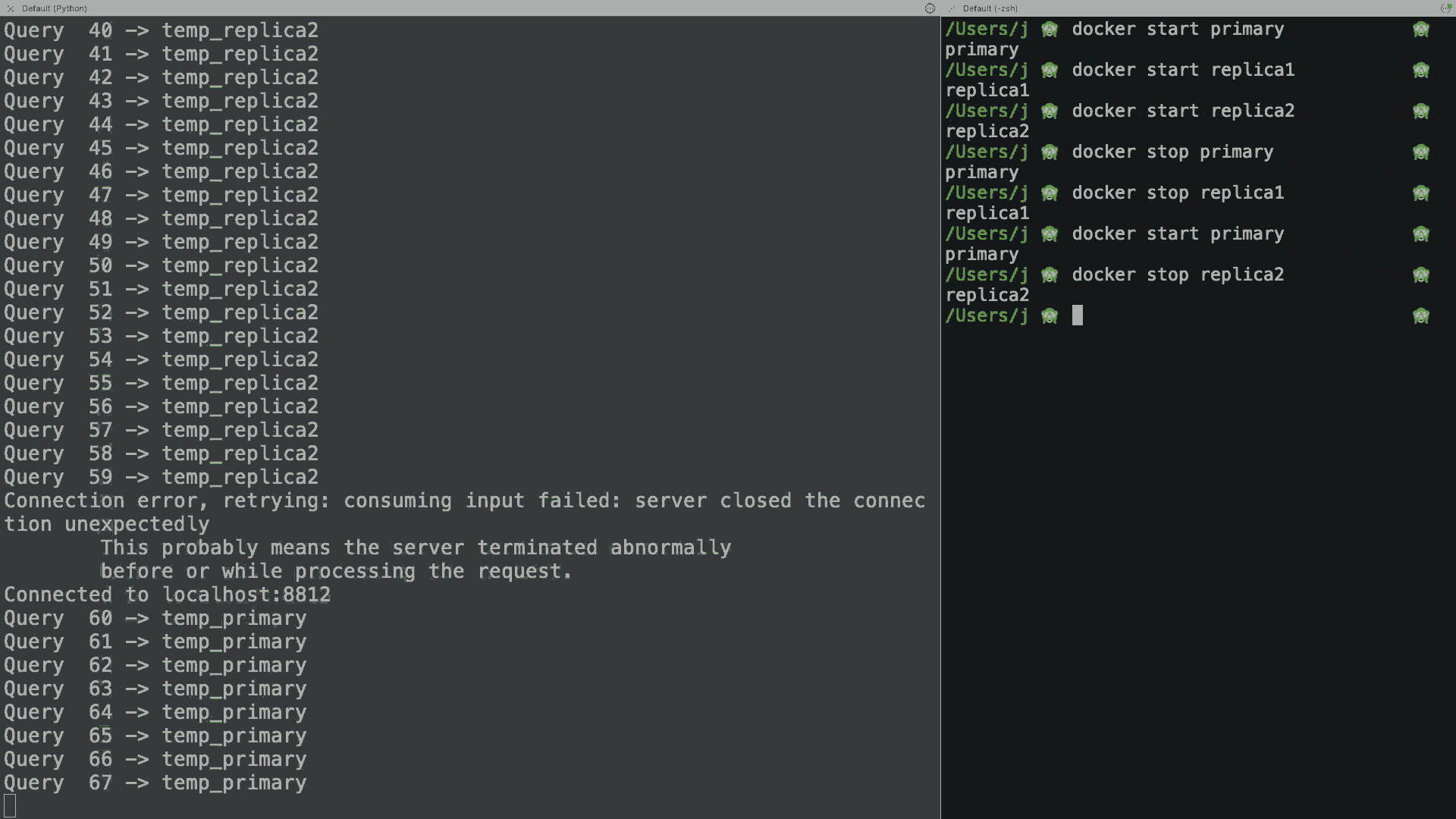
You can find a more complete implementation in the GitHub repo, as well as the Java, Go, Rust, C#, and C++ versions.
What about Node.js?
Node.js supports libpq-style multi-host connection strings only when using
pg-native (i.e. libpq bindings).
The default pg client (pure JS) does not support it. If you want cross-platform compatibility or don’t want to rely on
native bindings, you need to implement the failover logic manually.
You can build your own rotation logic: keep an array of hosts, and connect to the first one that responds. If the query fails, close the connection and try the next.
Here’s the key part:
const hosts = [{ host: 'localhost', port: 8812 },{ host: 'localhost', port: 8813 },{ host: 'localhost', port: 8814 }];let current = 0;async function connectToAvailableHost() {for (let i = 0; i < hosts.length; i++) {const { host, port } = hosts[current];const connStr = `postgres://admin:quest@${host}:${port}/qdb`;try {const client = new Client({ connectionString: connStr });await client.connect();console.log(`Connected to ${host}:${port}`);return client;} catch (e) {console.error(`Failed to connect to ${host}:${port}: ${e.message}`);current = (current + 1) % hosts.length;}}throw new Error('Could not connect to any host');}
Then you use connectToAvailableHost() to build your retry loop just like in the other examples. The example code
for NodeJs can be found at the demo repository.
Summary
High-availability reads are crucial for resilience, whether you're using QuestDB for market data, observability, or analytics.
✅ QuestDB Enterprise provides out-of-the box read replicas.
🧠 You can implement smart retry logic with minimal effort in most languages.
🧪 We’ve tested this in Python, Java, Node.js, Go, Rust, .NET, and C++. Find them all in the companion repo.
Give it a spin, pull the plug on your primary node, and watch your reads survive.